

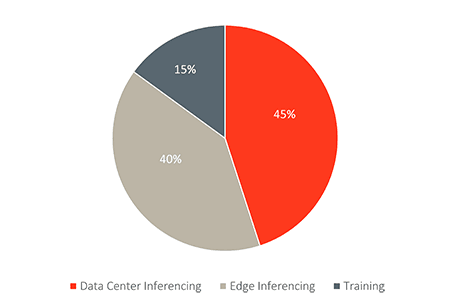
Did you know that up to 85% of AI silicon used today in data centers and at the edge is dedicated to AI inferencing? This is where a trained AI model takes the knowledge it has acquired to make predictions on new data.
On the flip side, a smaller fraction of AI silicon is reserved for AI training. This phase focuses on developing a model by feeding it vast amounts of data and tweaking its parameters until it can predict accurately.
Most AI training is better served by high-performance GPU products. Thanks to their vast memory bandwidth that significantly speeds up tasks, they also come with a hefty price tag and substantial power consumption, making them overpriced, overpowered, and overkill for tasks like AI inferencing.
Considering that most AI tasks are centered around inferencing rather than training, CPUs have become a smarter choice. In fact, CPUs can efficiently handle most inference workloads today. The mantra here is all about "rightsizing" your compute power to fit your AI models like a glove.
Enter Ampere Cloud Native CPUs. Their high performance combined with low power requirements makes them exceptionally suitable for inference workloads.
We invite you to join us in exploring why Ampere Cloud Native CPUs are becoming the preferred choice over GPUs for AI inference tasks, empowering your AI to operate more effectively and intelligently.
Revolutionizing GPU-Free AI Inferencing: Ampere's CPU-Driven Approach
At Ampere, we're passionate about revolutionizing AI inference with our groundbreaking GPU-free Cloud Native CPUs. This is achieved through the high compute density of Ampere processors, equipped with up to 192 single-threaded cores and double the vector units per core—allowing for predictable performance and unprecedented computational scaling.
In computational workloads such as AI, the reliance on these vector units is crucial to performance and is one reason the Ampere architecture is so efficient vs. legacy x86 processors. AI is a workload that particularly benefits from high computational scale, making the additional vector units in each core a valuable resource for vector math operations. This innovative architecture doesn't just crank up computational power; it does so with an eye on energy efficiency, striking a perfect harmony that fuels AI applications without draining resources.
For larger inference workloads that go beyond what CPUs can handle on their own, we've embraced domain-specific accelerators (DSAs). While DSAs provide a scalable and power-efficient AI solution, this move isn't just about scaling; it's about doing so efficiently and powerfully, ensuring that even the most demanding AI applications run smoothly without missing a beat.
So, how do Ampere CPUs compare to the competition? Whether in the cloud or on-premise, our CPUs lead the pack. In terms of inference per dollar in the cloud, particularly with Ampere-powered Oracle AI instances compared to other CPUs like AWS Graviton, we outperform the competition. Even against Nvidia's A10 instances, Ampere comes out on top. This trend continues when comparing our CPUs against the best from AMD Milan and Intel Ice Lake in discrete inference workloads.
Taking a closer look at specific applications, when running OpenAI's Whisper model — a cutting-edge speech-to-text transcription tool — Ampere CPUs offer up to 2.9 times the performance of Nvidia's GPU-based solutions. This stark difference highlights why Ampere CPUs are becoming indispensable for modern AI workloads, proving our commitment to delivering powerful, efficient, and cost-effective AI inference solutions.
Ampere CPUs: Increasing Power Efficiency, Slashing Costs, Enhancing Performance
In today's rapidly evolving tech landscape, data centers are paradoxically both advancing and stalling. While we've seen significant growth in capacity and some improvement in Power Usage Effectiveness (PUE) — hovering around 1.59 over the last decade — the advancements haven't kept pace with the increased power demands of modern server architectures, including both legacy x86 and the more energy-intensive GPUs.
This situation has left many data center operators struggling to keep up, as the industry seems to focus more on cutting-edge innovations rather than addressing the practical limitations faced by most facilities. Despite a near doubling in data center rack capacity over the past ten years, the average power per rack remains below 10 kW, with only a small fraction exceeding 20 kW, according to The Uptime Institute's 2022 survey.
Within this context, Nvidia’s introduction of the DGX H100 as a prominent solution in the AI space marks a significant development. It's a powerful tool designed for high-end AI training tasks and certain inference workloads, reflecting the company's ambition to lead in the AI hardware market. However, the high-power requirements and cost associated with the DGX H100 system make it a challenging option for most data centers to adopt.
For example, a rack of four DGX H100 can consume more than 41kW per rack and cost approximately $1.5M. This presents a stark contrast to more accessible and sustainable alternatives for AI inference. For instance, a single rack of 40 Ampere Altra Max servers can outperform a rack of four DGX H100 in inference throughput by 19%, with less than 15 kW per rack and a cost of approximately $290,000. Supermicro's inference and edge AI server promotions offer even more cost-effective solutions.
Let us consider a real-world use case. Imagine a data center operator managing a 1.5MW facility filled with 100 racks, each consuming 15kW, who decides it is time to upgrade 20 of those racks. These are not just any racks, but ones filled with aging, increasingly vulnerable Broadwell or SkyLake servers. In this scenario, the operator is considering three potential upgrades: AMD Milan, AMD Genoa, and Ampere Altra Max-based servers. To objectively compare these options, we have relied on a methodology where a 25% weighted average composite score is calculated across four common AI Inference workloads (BERT, DLRM, Resnet, and Whisper). These workloads have been rigorously tested by our Ampere engineering team to ensure a fair and comprehensive analysis.
The outcome of this comparison is quite revealing. Ampere Altra Max stands out from the competition, delivering an impressive performance per rack up to 2.5 times better than its rivals. But it is not just about raw power; Ampere Altra Max achieves this superior performance at a significantly lower cost.
Refresh Opportunity: Move to Cloud Native with Built-In Ampere® AI
1 MW Data Center with a PUE of 1.5 @ 15 Kw/Rack Refreshing 20 Racks of 6 Year Old Servers

These are conservative estimates, based on available public prices and use the average of publicly available power calculators for similarly configured systems.
Learn more
- Want to learn more about how Ampere AI? Check out our solutions page.
- For a deeper dive into how Ampere CPUs optimize AI workload performance, read our white paper.
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054


