
Looking Beyond SMT in the Cloud

The modern cloud has been at the forefront of innovation for the last decade. Cloud Service Providers (CSPs) have leveraged economies of scale and technologies like virtualization and high-speed networking to provide utility computing to the masses. IT departments in most companies today have OpEx budgets earmarked for the cloud, leading to enterprises and HPC shops moving workloads into the public cloud.
This rapid growth in the cloud has led to levels of optimization and innovation not seen in the computing market for a long time. Legacy approaches have been replaced by more modern techniques for today’s environment. From AWS’s development of the Nitro system to reduce datacenter overhead to Google’s development of the Tensor Processing Unit to accelerate machine learning workloads, today’s CSPs are compelled to seek out the last bit of performance to improve efficiencies, increase revenues and enable new usages.
What does this have to do with Simultaneous Multithreading (SMT)? Well, as legacy technologies get optimized or replaced, we believe SMT is a microarchitectural feature that has outlived its usefulness in the cloud.
The raison d’etre for SMT
SMT on CPUs has been around since the 1960s, when IBM first researched it as part of the ACS-360 project. Digital Equipment attempted to commercialize it decades later with the Alpha 21464. But it was Intel, with the Pentium 4, that finally brought it to market as Hyper-Threading. Hyper-Threading, at its core (pun unintended), allows more than one software thread to run simultaneously on each core. According to Intel, “this is done by exposing two execution contexts per physical core such that one physical core now works like two logical cores that can handle two different software threads.” A real-world analogy for SMT is two roommates sharing a single room apartment, leading to higher utilization of shared resources… like a bathroom.
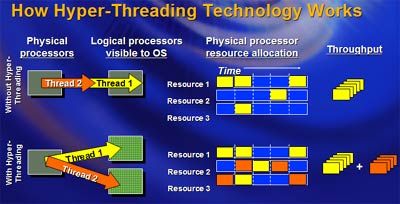
Figure 1: Picture courtesy Anandtech
As can been seen in Figure 1, Hyper-Threading allows the microarchitecture to make better use of the available execution units, especially when threads are waiting on data to be fetched from memory, which is orders of magnitude slower than the CPU. Since single-core processors were the norm when Hyper-Threading was developed, it (Hyper-Threading) could be considered a precursor to multiple cores on desktop CPUs. Given the relatively high frequencies at which CPUs were running at those days and the deep pipelines that made it possible to achieve those frequencies, keeping execution resources (i.e. the processor backend) busy was a challenge. Hyper-Threading did that, and with a minimal increase in power consumption.
So, what’s the catch?
Gaining efficiency improvements at the microarchitecture-level without any code changes (other than ensuring your application is multithreaded) is a desirable feature. So, what has changed? Two words – the cloud.
The myriad benefits the cloud provides to software developers and infrastructure teams (elasticity, low capex, scalability) are possible due to the economies of scale provided to the CSP. This is, in large measure, due to multitenancy – the ability to share a resource like a server among multiple customers, while ensuring isolation between their workloads. Multitenancy and workload isolation is made possible by virtualization, a technology that uses a thin layer of software, called a hypervisor, which allows a server to host multiple virtual machines (VMs), each of which can be rented out to different customers.
Problem #1 – Noisy Neighbors
Refer to figure 1 again. SMT worked well in that example because the two threads did not have overlapping requirements at the microarchitecture level. If thread 1 was waiting on data to be fetched from memory, thread 2 would use that free time to use the shared resources to perform arithmetic operations.
However, if the two threads sharing the execution resources were rented to two different customers and if there were times of the day when they both ran workloads with similar resource requirements, there is contention at the execution resource level. This could potentially affect either (or both) workloads, especially if they were sensitive to swings in latency.
Going back to our apartment analogy, if both tenants want to take showers at the same time and there is only one bathroom, one of them could end up waiting and possibly being late to work. Let’s look at a real-world example.
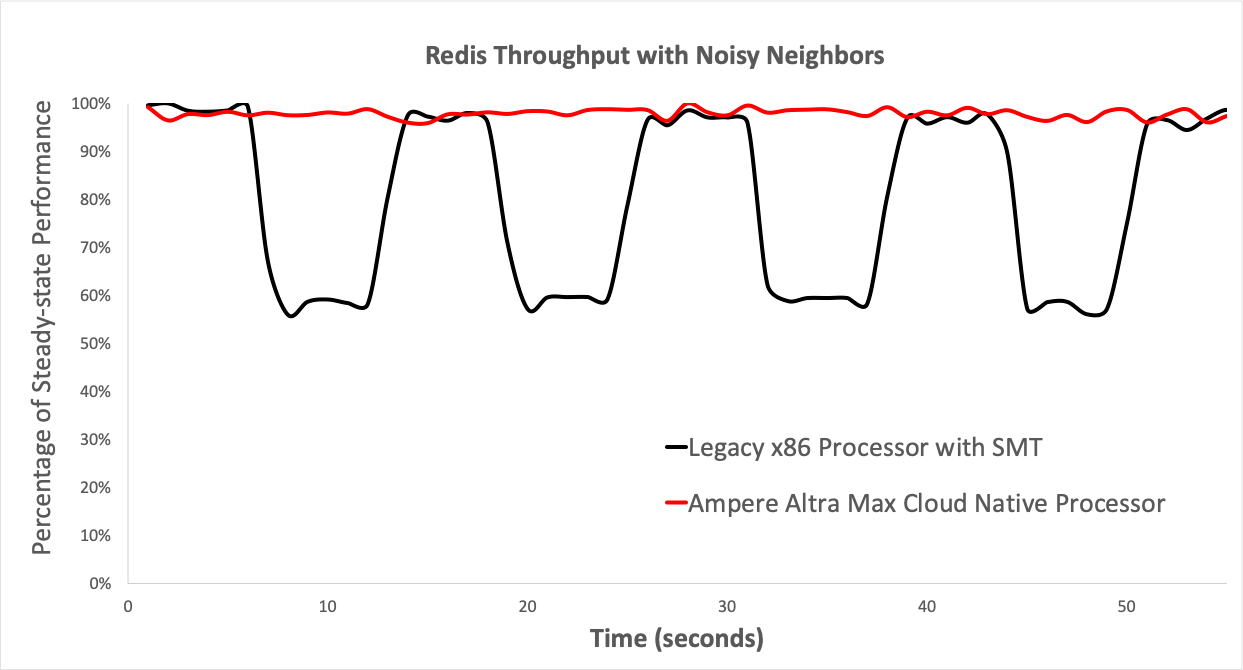
Figure 2: The effect of noisy neighbors on CPUs with and without SMT Redis is an in-memory key-value store, commonly used in the cloud. It is known for predictable low latencies and high throughput. It is also very sensitive to noisy neighbors. In our tests, we ran Redis on a specific core with affinity. A noisy neighbor was introduced periodically on the neighboring vCPU. On the x86 processor, that is a sibling SMT logical thread while on the Ampere Altra Max (which is SMT-free), any of the other cores on the processor can be chosen because they are all physical cores.
Figure 2 plots the throughput of the Redis instance over time on an Ampere® Altra® Max-based server and an x86 processor-based server with SMT. As can be seen in the graph, the presence of the neighbor introduces contention for shared resources at the microarchitecture level, thus affecting the performance of Redis.
SMT results in lower and more variable performance for each individual user in today’s multitenant cloud, a usage that it was not designed for.
Problem #2 – Security
As multi-tenant cloud environments become commonplace, SMT has become a security risk since multiple hardware threads share common resources like caches and execution units. Recent side-channel attacks such as Spectre and Meltdown have demonstrated how nefarious actors can use microarchitectural states to break down the isolation between different applications and steal confidential data. This is the equivalent of your roommate being able to rummage through your medicine cabinet when you’re not home. This is made worse by the fact that you wouldn’t even know it had occurred.
SMT increases the attack surface for such exploits and reduces security in cloud environments. This has led to several CSPs either disabling SMT or ensuring that the granularity of allocation is two virtual CPUs, offsetting any user density benefits created by SMT in the first place.
Why not turn SMT off on legacy CPUs then?
It stands to reason that, given SMT doesn’t duplicate resources, if disabled, the two problems outlined above should disappear. In some ways, but there are some new problems that CSPs must deal with.
Lower performance
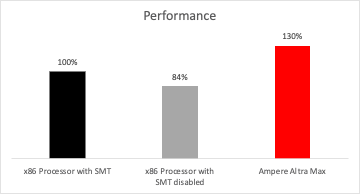
Figure 3: Redis Performance
As mentioned earlier, SMT provides some upside in performance on legacy CPUs. When disabled, workload performance is likely to drop. Figure 3 shows the drop in aggregate Redis throughput at a socket level with an x86 processor when SMT is disabled.
Lower Performance/Watt

Figure 4: Redis Performance/Watt
Figure 4 shows the performance/watt on Redis with and without SMT on legacy CPUs. Since SMT is no longer able to help better utilize spare cycles on inefficient x86 cores, energy efficiency drops.
Lower VM Density
Once SMT is disabled, half of the available logical processors on x86 processors disappear. For processors already struggling to keep up with the high-density requirements of the cloud, capacity is now even further constrained. VM density (measured in vCPUs) drops by 50%, reducing revenues for CSPs and increasing Total Cost of Ownership (TCO) by almost that much, if not more.
If your apartment building were to enforce a ‘one person per apartment’ policy, the number of tenants per building would drop drastically. However, if built properly, the apartment would match the tenant – and landlord – needs from the start.
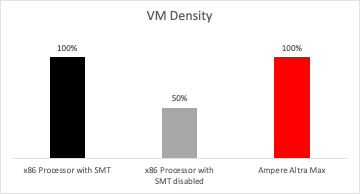
Figure 5: Virtual Machine Density with and without SMT
A better path forward - Cloud Native Processors
To summarize, SMT has value in certain markets, like single-user client PCs and workloads where predictability of performance is not as important as raw performance. It can better utilize the inefficient microarchitectural resources of legacy x86 processors in exchange for a modest increase in power consumption. However, it adds variability and security risk in multitenant environments like the cloud, an unacceptable tradeoff.
Disabling SMT on legacy processors leads to other problems – lower performance and energy efficiency, higher TCO and lower capacity (i.e. revenue) for CSPs. If a processor was designed with SMT, whether you use it or not, you’re paying a penalty.
The real solution to the problem is designing efficient cores that are single threaded to begin with, having a lot of them, and doing all of this with higher levels of energy efficiency and area efficiency. The data shared in this blog demonstrates how well Ampere Altra Max does on Cloud Native workloads on all three vectors – predictable performance, performance/watt and VM density. The die space efficiency also allows Ampere Cloud Native Processors to have twice as many physical cores as competitive x86 CPUs without having to rely on SMT to artificially inflate the logical core count.
Thanks to Ampere’s Cloud Native Processors, CSPs now have the option of choosing high performance, high efficiency and higher capacity without making unacceptable compromises. Cloud developers have access to physical single-threaded cores in the cloud, leading to predictable performance and lower security risk.
At Ampere, we work on cutting edge technologies designed for the modern cloud, unencumbered by legacy technologies, and firmly focused on what comes next!
To hear more on this topic, listen to this podcast on Amplified by Ampere.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



