
Ampere® Powers Real-Time Multimodal AI Inference at the Edge — Without GPUs

At Embedded World 2025, Ampere redefined what edge AI can look like: real-time multimodal AI inference — computer vision and natural language processing — running entirely on a single Ampere® Altra® CPU. No GPUs. No specialized accelerators. Just one processor executing two distinct AI workloads in parallel with consistent, production-grade performance.
In the live demo, the system processed two video streams with a computer vision model while simultaneously powering an AI chatbot that answered questions about the visual data. Both workloads ran concurrently – with View System’s View AI running on a fourth of the CPU’s 128 cores, and the object detection demo running on a fraction of the remaining cores. All in all, the system was drawing only 95 watts. There was no degradation, no interference, just smooth, responsive performance throughout.
Inside the Demo: Vision & Language on One Platform
The use case simulated a factory setting. A computer vision model tracked items on a conveyor belt using two recorded video streams. Simultaneously, a View System’s View AI — powered by retrieval-augmented generation (RAG) — allowed users to ask natural language questions about what the system was seeing.
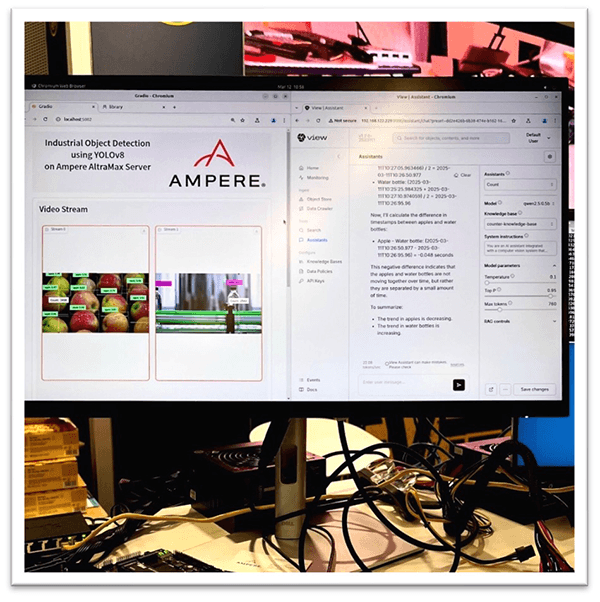
Both AI workloads — vision and language—ran in parallel on a single Ampere® Altra® Max CPU, with real-time data from the vision model feeding directly into the chatbot’s responses. The result: instant, conversational insight into live operations — no reports, no dashboards, no delay.
The Architectural Advantage: Predictability at Scale
The demo ran on an Ampere Altra Max 128-core processor, with 32 cores (see cores 64-95 in the below image) dedicated to the chatbot. The remainder of the cores were left open/unassigned to handle the computer vision workload. Ampere’s architecture — featuring single-threaded cores and large per-core cache — enabled both inference tasks to run in parallel with no resource contention. This separation allowed the system to operate with consistent responsiveness, even under real-time load. As seen below, cores 0-63 and 96-127 all run at less than 3% utilization.
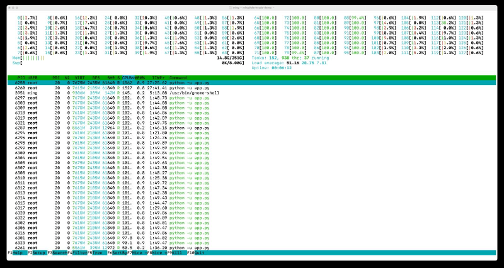 Running htop command under full load
Running htop command under full load
With plenty of unused cores and low power draw, the platform offers room to grow — whether that means adding more camera feeds, more users, or more use cases — without rethinking the infrastructure.
The demo also leveraged Ampere’s AIO software accelerator to further boost inference speed, without relying on additional hardware.
Implications for Edge AI Deployments
This demo wasn’t just a technical win — it showed how edge AI can become dramatically more practical.
By removing the GPU from the equation, Ampere simplifies deployment and lowers cost. Traditionally, this type of deployment would require two separate GPUs to run the different inference workloads. With just a single CPU drawing under 100 watts, the system becomes less complex, more affordable and is very energy efficient — making it ideal for deployment near the source of data, whether that's on a factory floor, in a remote enclosure, or inside an industrial cabinet.
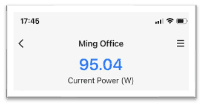 Power meter reading under full load
Power meter reading under full load
That opens the door to smarter, faster decision-making. Instead of digging through reports or dashboards, a shift supervisor could simply ask how many units were processed during a shift or whether production is trending up — and get an immediate answer based on live sensor data.
The demo was made possible through collaboration with View Systems, who delivered View AI; Arcee, who delivered the small language models that powered the chatbot; ADLINK, who provided the edge-ready Ampere Altra Dev Kit; PICMG, whose COM-HPC design standard shaped the underlying hardware platform; and DevHeads for technical marketing and promotion. Together, they helped Ampere show that AI at the edge isn’t just viable — it’s deployable.
Interested in deploying this yourself? Check out our Github repo with configuration instructions. Stay up to date on developer discussions by joining our Developer Community!
Disclaimer
All data and information contained herein is for informational purposes only and Ampere reserves the right to change it without notice. This document may contain technical inaccuracies, omissions and typographical errors, and Ampere is under no obligation to update or correct this information. Ampere makes no representations or warranties of any kind, including express or implied guarantees of noninfringement, merchantability, or fitness for a particular purpose, and assumes no liability of any kind. All information is provided “AS IS.” This document is not an offer or a binding commitment by Ampere.
System configurations, components, software versions, and testing environments that differ from those used in Ampere’s tests may result in different measurements than those obtained by Ampere.
©2025 Ampere Computing LLC. All Rights Reserved. Ampere, Ampere Computing, AmpereOne and the Ampere logo are all registered trademarks or trademarks of Ampere Computing LLC or its affiliates. All other product names used in this publication are for identification purposes only and may be trademarks of their respective companies.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



