
Llama me impressed! AI is expensive, but it does not need to be

For years, AI enthusiasts believed that powerful and costly GPUs are essential for training and running complex large language models (LLMs) like ChatGPT and Llama 2. But the landscape is changing. Recent advancements and optimizations are making it surprisingly feasible to run LLMs on cloud-native CPUs – with impressive performance and cost advantages. This revelation has come as a shock to many, especially considering the usual reliance on expensive, power-hungry GPUs. A recent blog post by OCI highlighted their success in running an optimized 7B Q4 Llama2.cpp model on Ampere-based CPU instances. This demonstrated the real-world potential of CPU-based LLM solutions.
We recently ran an experiment with an OCI Ampere A1 flex VM (64 cores) to benchmark Llama 2. Using a prompt size of 128, an output size of 64, and varying batch sizes (1, 4, 8), we were impressed by the results! We generated 33-99 tokens per second – much higher than anticipated. This made us question: How does this performance stack up against other processors? Is there hidden potential in Cloud Native CPUs for running LLMs effectively? This sparked our curiosity to investigate further.
To get a better understanding of our initial comparative CPU benchmark results, we used an AWS m7g.16xlarge instance and ran Llama 2 on their Arm-based Graviton 3 processor (with 64 cores). We kept the parameters (prompt size 128, output 64, batch sizes 1, 4, 8) consistent for a fair comparison. The AWS instance yielded 29-88 tokens per second – similar performance to OCI A1, but slightly slower. This stemmed from the AI optimizations Ampere/OCI had implemented, as well as underlying differences in the processor architectures.
The decisive moment had arrived. How would the CPUs fare against a reigning GPU? We fired up an AWS g5.4xlarge instance (equipped with an A10 GPU) and ran Llama.cpp. The results were eye-opening: 32-176 tokens per second. Interestingly, the GPU performed worse than the CPUs for smaller batch sizes (1 & 4). However, it surged ahead when the batch sizes increased 8, displaying its raw power for larger workloads.
While raw performance matters, the true test for large-scale AI deployments is performance per dollar. The bottom-line is key – how much AI can we get for our investment? To bring this into focus, we calculated the cost of generating 1 million tokens on each of the instances we tested. Let us look at the results:
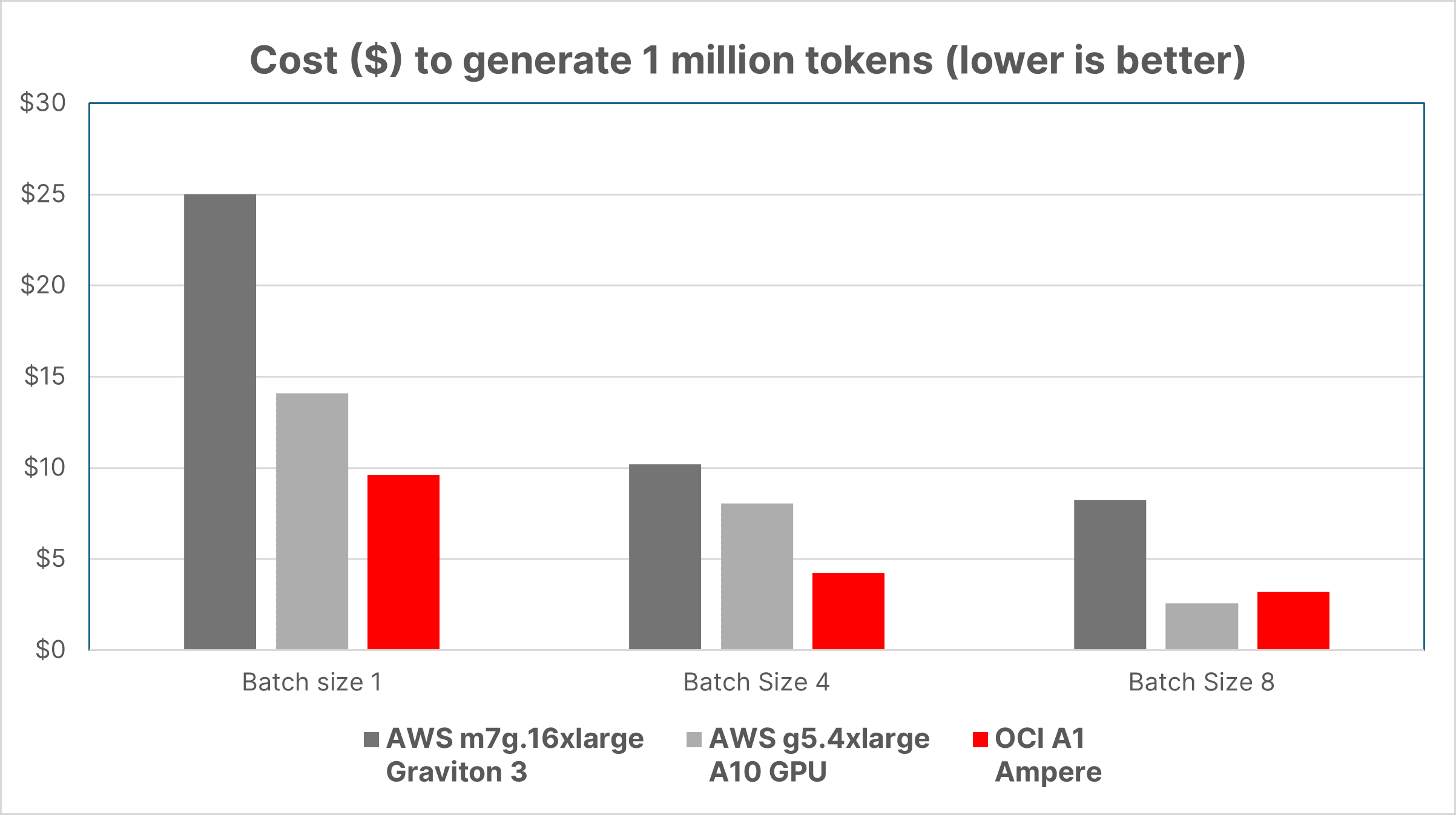
The cost analysis reveals a key takeaway: Ampere Cloud Native CPUs lead cost-effectiveness. In fact, the Ampere-based OCI A1 instance provides up to 2.9x price/performance advantage over similar Graviton 3 CPU instances. Compared to the GPU, the A1 instance exhibited up to a 47% better cost/performance advantage for batch sizes 1-4 and similar at batch size 8.
This reinforces the importance of evaluating both performance and cost when selecting the ideal AI hardware solution. The perception of AI as inherently expensive is changing. Through optimizations, strategic hardware choices, and a focus on cost-effectiveness, AI can deliver incredible value without excessive costs.
Let me know if you would like to explore specific use cases where the cost-benefit ratio of Cloud Native CPUs is particularly compelling!
Try it out yourself, OCI is offering one free VM A1 Flex Shape (64 OCPU and 360 GB memory) for three months to customers who sign up before December 31, 2024. Sign up today to take advantage of this limited time offer here.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



