
Breaking Boundaries: AmpereOne’s Disaggregation Strategy for the Next-Gen Cloud

AmpereOne® is a revolutionary leap forward in computing technology. This innovative product is strategically designed to disaggregate compute, memory and PCIe subsystems and deliver unparalleled performance and efficiency. By meticulously creating distinct scalable units and aligning each component with the most optimized manufacturing process, AmpereOne sets a new benchmark for power-efficient, high-performance computing. This modular approach aligns well with modern cloud workloads and cloud-native applications.
AmpereOne’s Compute Chiplet is built on TSMC’s 5nm process and contains the cores, caches, and coherency engines. The PCIe and memory controllers each have their own I/O chiplets, are built on TSMC’s 7nm process and consist of the appropriate controllers and PHYs.
Ampere has developed its own custom die-to-die interconnect to connect these dies together, with up to 2.8TB/s aggregate bandwidth in each direction. The disaggregation approach is designed to enable flexibility and efficiency.
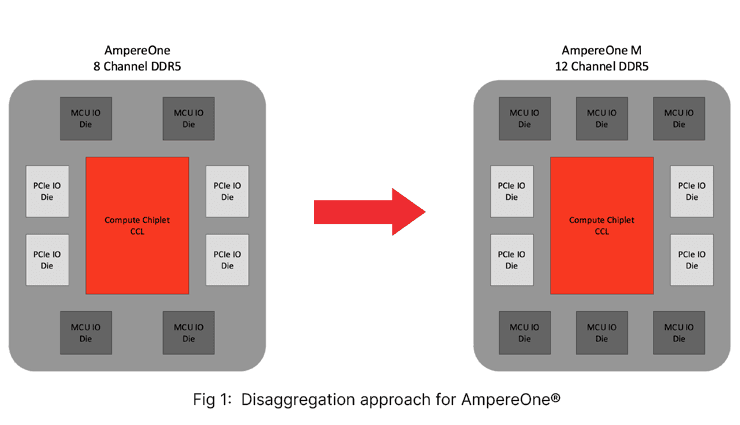
Ampere announced the 12-channel AmpereOneM in the May announcement video earlier this year, as the next processor beyond AmpereOne. Using the modular architecture, a 12-channel platform can be created using the same building blocks as an 8-channel platform (Fig 1). This approach allows Ampere to rapidly integrate customer intellectual property and customize I/O to different applications and customers.
The Compute Chiplet: Consists of a core cluster, which is a group of 4 Ampere custom cores. This cluster is repeated and arranged in columns: 6 columns with 8 clusters each, for 192 cores (Fig 2).
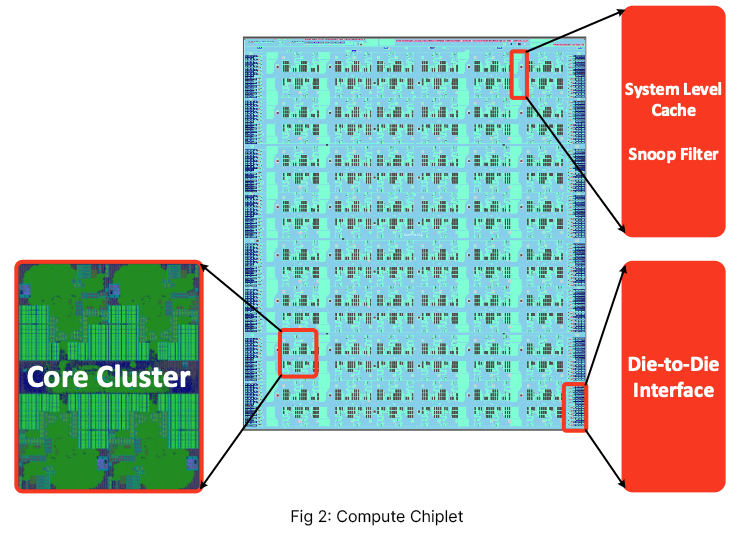
Each coherency engine contains system level cache and snoop filters. A block of two coherency engines is repeated and arranged in columns, for 64MB of system-level cache and snoop filters to track the 384MB total L2. The die-to-die interface is used to connect to the I/O dies. All these components are linked with a fully connected 8x9 mesh, providing up to 5.7 TB/s of cross-sectional bandwidth.
I/O Chiplets: The Compute Chiplet is connected to the MCU and PCIe I/O dies (Fig 3). Each MCU die supports 2 channels of DDR5, with four dies providing eight channels of DDR5. The PCIe die provides 32 lanes of PCIe 5.0.

Each chiplet has eight controllers to support different levels of bifurcation, so in total AmpereOne supports 128 lanes of PCIe 5.0.
Ampere’s approach to compute-memory-IO disaggregation is well aligned with cloud-first design principles, providing the benefits of price-performance, power efficiency and scale for a variety of workloads, including artificial intelligence (AI) inferencing, databases, media transcoding, web services etc. The low latency interconnects minimize communication overhead and power consumption between compute units and memory. This disaggregation of compute and IO chiplets lead to a more efficient utilization of processing power, critical in high-core count AmpereOne processors.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



