

DSB Social Network Scale Out Brief
Web Services Efficiency
Greater Efficiency for Web Services with Ampere Altra Processors
This solution brief examines real-world web service solutions running on Ampere® Altra® Cloud Native Processors at scale. An important requirement of web services and the Cloud at large is scalability. In order to facilitate an efficient scale-out deployment, modern web services make use of a micro-service architecture and often use containerized deployment – a topology commonly referred to as Cloud Native. A container orchestration engine like Kubernetes is an increasingly popular tool for building scalable infrastructure. Kubernetes helps automate, scale, and manage containerized web applications using built-in schedulers, replication controllers and load-balancing techniques.
We evaluate one such web service, the Social Network application which is part of the DeathStarBench (DSB) suite developed at Cornell University. The social network application simulates a large-scale real-world application like Twitter or Facebook. We deploy and scale this complex service on a multi-node Kubernetes cluster and measure the scalability and performance as expressed by end-user latency and total throughput. The results compare the performance and energy savings while running the web service on an Ampere Altra Max cluster compared to an x86 based cluster using Intel 6342 (Ice Lake) servers.
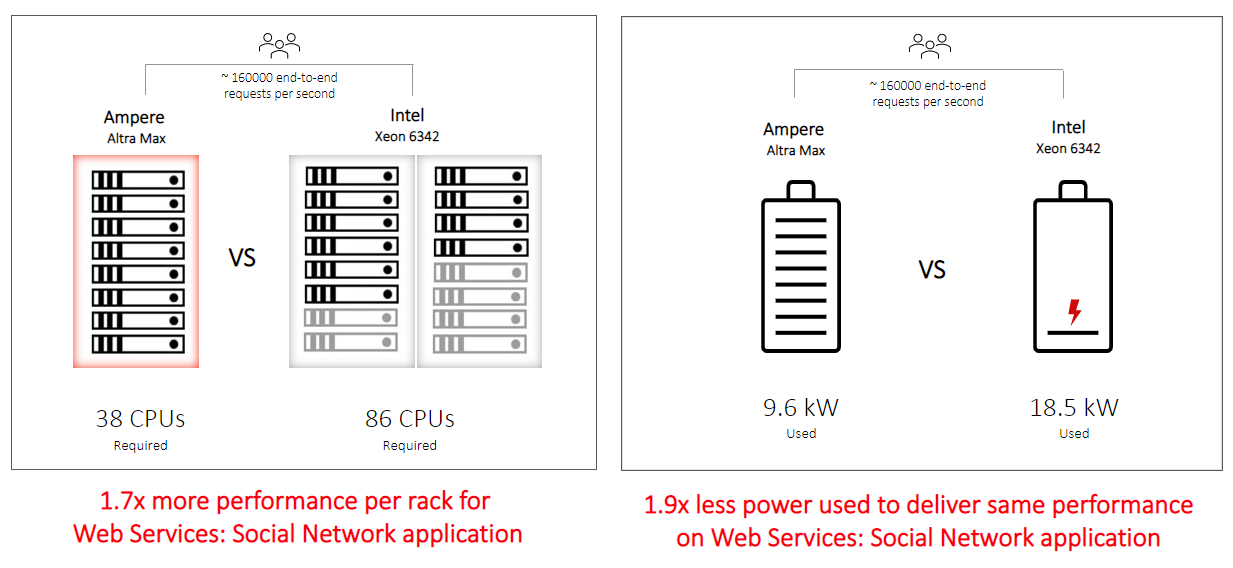
In this setup, Ampere’s efficient processors enables 1.7x more performance per rack – equivalent to serving 70 percent more requests (throughput) to the social network web service. As a result, Ampere Altra Max processors reduce the number of racks required for these types of web services running at scale. In turn, deploying fewer racks further reduces the total datacenter footprint as less total support infrastructure (switches, square footage, cooling, water, human support) is required.
Running the Social Network Web Service on Ampere Altra Max
Ampere Altra Max processors are designed to deliver exceptional performance for cloud native web services like a social networking application that needs the capacity to scale and handle several million user requests per second (RPS) simultaneously. Cloud Native Processors use an innovative architectural design, operate at consistent frequencies, and use single-threaded cores that allows workloads to scale out and run in a predictable manner with minimal variance under heavy load. The processors are also designed to deliver exceptional energy efficiency translating into industry leading performance per watt (at the individual server level) and performance per rack at scale. The aggregate energy savings lowers operating costs and yields a much lower carbon footprint.
Introduction
The DeathStarBench/socialNetwork application is deployed on a Kubernetes cluster using helm charts. We use the Kubeadm tool to set up a minimum viable cluster that conforms to best practices. The cluster is comprised of 3 nodes: the control-plane and 2 worker nodes. The control-plane node is also configured to act as a worker node and can schedule pods. The flannel container network interface (CNI) add-on is deployed for the pods to communicate. All the nodes are interconnected on an internal network.
| Architecture | Ampere | X86_64 |
|---|---|---|
| Model | Ampere Altra Max | Intel Xeon 6342 |
| Cluster | 3 node cluster | 3 node cluster |
| Cores | 128 | 48 |
| Threads | 128 | 96 |
| Memory | 512G | 512G |
| Operating System | Ubuntu 22.04 LTS | Ubuntu 22.04 LTS |
| Network | 25GbE | 100GbE |
| Storage | Samsung NVMe 960GB | Dell NVMe 960GB |
| Kernel Version | 5.15.0-60-generic | 5.15.0-60-generic |
| Kubernetes Version | 1.23.16 | 1.23.16 |
We simulate the load on the cluster using a load generator tool (wrk2). The load is gradually scaled up to find the maximum throughput before the cluster violates a predetermined SLA of 2 seconds p99 latency. And finally, we compare the maximum throughput, performance per rack and energy savings on a multi-node Ampere Altra Max cluster to a similar setup that uses Intel Xeon 6342 based systems.
Emulation of a Real-World Web Service Using wrk2
The DeathStarBench suite uses wrk2 – which is wrk modified to produce a constant throughput load, and precise latency measurements up to five 9s of accuracy. Wrk2 comes with LuaJIT scripts that simulate user actions such as connecting to the social network application, composing posts, accessing user and home timelines, following other users, among other activities. We ran wrk2 on a separate client system connected to the Kubernetes cluster on an internal network to avoid load contamination. The actions were chosen to emulate a mixed workload that combines reads and writes to simulate a real-world scenario. The social graph for the application is initialized from a small network dataset (Reed98 Facebook networks) by registering users and adding follow actions. The wrk2 load is then run with 1000 parallel connections and a constant throughput R-value starting at 5000 RPS on a single node cluster. Each test is repeated 5 times with the same throughput R-value. The latencies and achieved throughput are recorded for each iteration for statistical analysis. The wrk2 load is increased gradually in increments of 500 RPS, repeating the measurements for latency and throughput for each successive group run of 5 iterations. This process is repeated on 1-node, 2-node, and 3-node clusters to compare the effects of multi-node configurations on scale-out linearity. The tests are run in an identical manner on the Ampere Altra Max and Intel Ice Lake 6342 clusters.
Simulated Web Service Multi-node Cluster Benchmark Results
As with any web service that handles user requests, it is ideal to set a baseline for measuring peak performance using a service level agreement (SLA). We set an SLA measured in p99 latency of less than 2.0 seconds – that is to say, we target 99% of user requests to resolve in 2.0 seconds or less.
The above chart shows a comparison of response times as load on the web service is gradually scaled up. The p99 latencies indicate that users accessing the social network site on the Altra Max cluster received a 77% faster response when compared to users accessing the web service on the x86 cluster at peak load. When the RPS load on the web service is increased and the cluster is scaled to use more nodes, the Altra Max cluster still has 64% faster response time than the x86 cluster.
We extend the 3-node cluster data to the rack level (42U with 12kW power budget, leaving room for network and other equipment) to calculate efficiency at the rack level. When comparing a full rack of servers dedicated to running web services like the social network application, we observed one rack of Ampere Altra Max servers was capable of delivering 1.7x more throughput measured as total requests per second while still delivering p99 latencies within SLA target. We measured the system power usage during peak load on both the clusters and extended the data to a full rack, results show Ampere servers deliver 1.9x higher performance per Watt of energy used compared to x86, which is an indicator of the superior power efficiency of the Cloud Native Processor. Combining the higher performance and the power efficiency results in much smaller rack footprint for the Ampere Altra Max servers compared to the Intel Xeon 6342 cluster. Ampere Altra Max servers can deliver the same throughout using less than half the racks as compared to legacy x86 servers.
The distribution of response times for any web service is a good measure of predictable performance. When plotting the latencies from a single test on the 3-node cluster as a bell curve (normalized distribution), the response time for all requests on Altra Max cluster fall within a much narrower range than the Ice Lake cluster. This indicates that the Altra Max cluster delivers a more consistent, faster, and uniform end-user experience even under stressful load conditions. Compare this to the 3x higher deviation in response times on the x86 cluster resulting in 3x worse performance in terms of predictability.
Key Findings and Conclusions
As discussed earlier, in recent years growing demand for web services and cloud-native technologies resulted in increased rack sprawl in data centers. In order to meet this demand, it is important for the infrastructure to scale, but scaling sustainably is the key.
Lower power consumption combined with superior performance of Ampere Altra Max CPUs means less Ampere-powered racks are needed to run the same workload compared to Intel server racks. In fact, our findings reveal that in order to achieve the same performance for web services on 1 rack of Ampere-based servers will require 1.5 racks of the Intel based servers. Additionally, the x86 racks consume approximately 1.7x the power in order to deliver the same number of requests per second.
These results for a fully functional Web Service closely parallel the findings in our composite model of a web service stated in the recently released eBook and Infographic. These results are significantly more sustainable and can reduce the overall resource footprint of a modern web service deployment by over 50%. This kind of advantage is truly disruptive, making the Ampere Altra family the most sustainable processor for modern cloud infrastructure.
About Ampere and Web Services on Ampere
The key benefits of running web services on Ampere Altra Max processors are:
-
Increase Throughput: Ampere Cloud Native Processors allow organizations to fit their key workloads to cloud native HW architecture, outperforming legacy x86 and delivering 1.7x or better performance per rack on complex web services like a the DSB Social Network tested here.
-
Conserve Rack Space: As workloads scale out, performance and power advantages on Ampere Altra Max combine to deliver unprecedented performance per rack for the most demanding workloads. The rack space required to deliver an equivalent web service capacity can be a third of that required by legacy x86 processors.
-
Lower Power Consumption: The inherently lower power consumption and high core count of Ampere Altra Max Cloud Native Processors mean adding less CPUs, fewer racks and less power consumed as you scale out your workloads. In this study alone, the power required at scale was cut in half.
Architecturally unique Cloud Native Processors deliver the level of power efficiency and performance needed to meet the sheer volume of cloud workload growth and aggressive sustainability goals.
Footnotes
As part of web services performance benchmarking, we observed run to run variations in the measured latency and throughput due to the randomness built into the load generator. In order to minimize the effects of these variations, we ran each test 5 times and used the geomean of the measured latency and throughput for our final calculations.
Disclaimer
All data and information contained in or disclosed by this document are for informational purposes only and are subject to change. This document may contain technical inaccuracies, omissions and typographical errors, and Ampere Computing LLC, and its affiliates (“Ampere”), is under no obligation to update or otherwise correct this information. Ampere makes no representations or warranties of any kind, including express or implied guarantees of noninfringement, merchantability or fitness for a particular purpose, regarding the information contained in this document and assumes no liability of any kind. Ampere is not responsible for any errors or omissions in this information or for the results obtained from the use of this information. All information in this presentation is provided “as is”, with no guarantee of completeness, accuracy, or timeliness.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



