
Data Analytics
Data Analytics
Batch processing and analytics work best on Ampere processors
Batch processing and analytics work best on Ampere processors
Big Data solutions require massive computational power along with persistent and high performance storage and network resources.
Ampere® Altra® processors, designed for cloud native usages, provide consistent and predictable performance for big data solutions. Their high core count, compelling single threaded performance, and consistent frequency make big data workloads scale out very efficiently. Ampere processors have much lower power consumption over legacy x86 processors. Low power and high core density per rack translate directly into both Capex and Opex savings.
Key Benefits
Key Benefits
Scalability
Scale out with confidence! In our Hadoop TPCx-HS testing ( Graph 1) we observed near linear scaling through a total of nine nodes. This data was captured on the Amper Altra based Hammerhead Bare Metal Cluster. If you have a scale-out workload you would like to run on a high performance cluster you can request access on our Hammerhead Cluster
Cloud Native Performance
Ampere Altra processors are a complete system-on-chip (SOC) solution built for Cloud Native applications. Graphs 2 to 4 depict the Spark and Hadoop, TPC-DS and Terasort wokloads on VM's. Ampere VM's performed well above its peers. Spark Terasort performed 73% better than Intel Skylake and 13% better than AMD Milan(Graph 4).
Consistency and Predictability
Ampere processors provide consistent and predictable performance of Big Data solutions and for bursting workloads.
Power Efficiency
Ampere processors have industry leading energy efficiency, and consume much lower power than competition.
System configurations, components, software versions, and testing environments that differ from those used in Ampere’s tests may result in different measurements than those obtained by Ampere. The system configurations and components used in our testing are detailed here
Architecture
Architecture
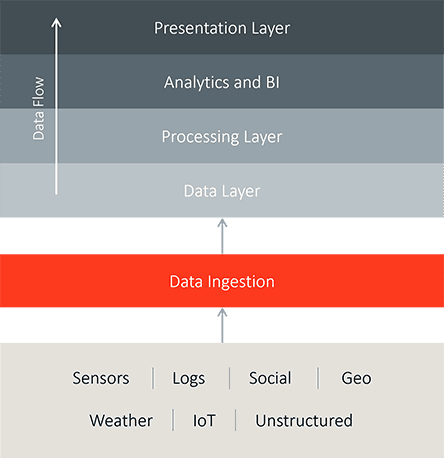
Big data architecture is designed to handle the ingestion, processing, and analysis of large and complex data. Big Data workloads manage large amounts of data, analyze it for business purposes, steer data analytics operations for business intelligence, and orchestrate the big data analytics tools to effectively extract vital business information from extremely large data pools.
Big data solutions include the following types of workloads:
- Batch processing of large data sources at rest.
- Real-time processing of large amounts of data in motion.
- Interactive exploration of big data sets.
- Predictive analytics and machine learning.
Data Sources include:
- Static files like application log files
- Application data stores
- Structured and unstructured data sets
- Real-time data sources like IoT devices.
Distributed data stores are essential components of the solutions. Data stores range in size from gigabytes to petabytes of data in many different formats. Big data applications process these files using long running batch jobs to filter, aggregate and format the data for later consumption by data analytics.
Components
Components
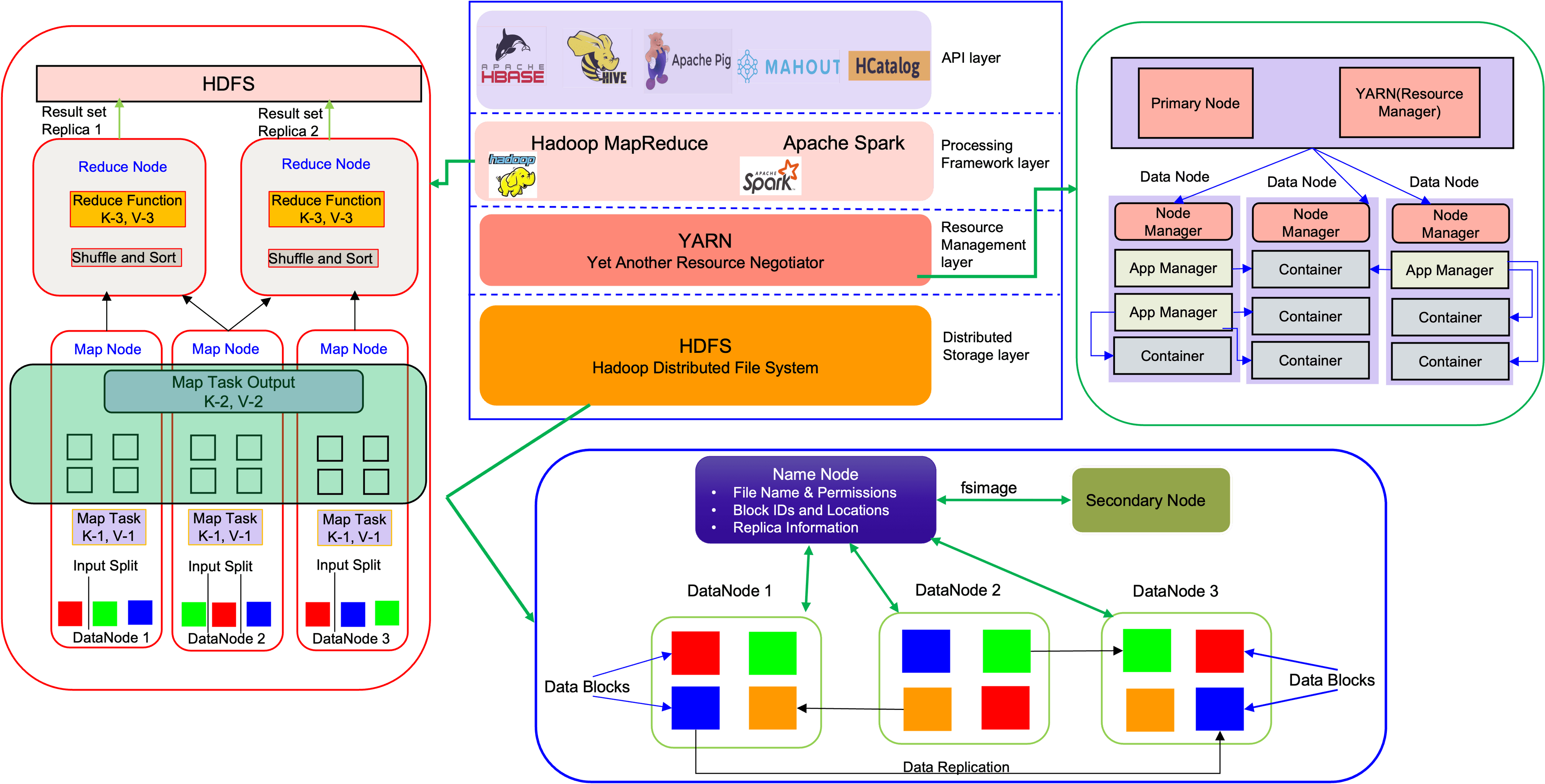
HDFS(Hadoop Distributed File System)
Hadoop Distributed File System (HDFS) is a component of Big data storage layer. The files in HDFS are broken into block-size chunks called data blocks that are replicated within the cluster for storage resiliency.
YARN(Yet Another Resource Negotiator)
YARN manages the resources for the applications. YARN decouples MapReduce’s management and scheduling capabilities. YARN has multiple nodes to resume execution in case of failure of the first node.
MapReduce
MapReduce's algorithm distributes the job and runs it across the cluster. Single tasks are divided into multiple tasks and run on different machines.
Hadoop
Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware.
Spark
Apache Spark is used for executing data engineering, data science, and machine learning on single-node machines or clusters. It utilizes in-memory caching, and optimized query execution for fast analytic queries against data of any size. It provides API’s in Java, Scala, Python and supports multiple workloads in real time analytics, batch processing, interactive queries, and machine learning. Spark addresses the limitations of MapReduce by doing in-memory processing and reusing data across multiple parallel operations. Spark relies on other storage systems like HDFS, Couchbase, Cassandra and others
Hive
Hive is a distributed data warehouse system. Hive is used to process mostly structured data in Hadoop. Hive allows users to read, write, and manage petabytes of data using SQL. Hive can query large datasets leveraging MapReduce.
Pig
Pig is used for the analysis of large amounts of data. It is a procedural data flow language that operates on the client side of the cluster. It can handle semi-structured data as well.
HBase
HBase is a columnar database that runs on top of HDFS. HBase provides a fault tolerant way of storing data sets and is well suited the process large volumes of random read and write data in real time.
Mahout
Mahout is a library of machine learning algorithms implemented on top of Apache Hadoop and using MapReduce. Mahout provides the data science tools to automatically find meaningful patterns in big data sets.
HCatalog
HCatalog allows you to access Hive Metastore tables with Pig, Spark, and Custom MapReduce applications. It exposes REST API and command line Client to create tables and other operations.
Ambari
Apache Ambari is a open source platform that simplifies the provisioning, management, monitoring, security of an Apache Hadoop cluster by providing an easy to use web UI and REST API. It provides a step by step wizard for installing Hadoop servives.
Zookeeper
Zookeeper provides operational services in Hadoop Cluster. Distributed applications use Zookeeper to store metadata, and use as a distributed configuration service and a naming registry for distributed systems.
Oozie
Apache Oozie is a workflow tool. You can build the workflow with dependencies of various jobs that are bound together and submitted to Yarn as one logical entity. Oozie is like a cron and submits the job to Yarn which executes the job.
Frameworks
Frameworks

Hadoop
Hadoop
Hadoop is open-source framework to store large data sets from gigabytes to petabytes. Hadoop is designed to scale up from a single computer to thousands, each offering local computation and storage.
Spark
Spark
Apache Spark is an open source, distributed processing system used for Big Data workloads. Unlike hadoop that reads and writes files to HDFS, Spark processes data using in-memory caching using RDD (Resilent Distributed Dataset ).
FAQs
FAQs
Resources
Resources
Briefs
Reference Architecture
External Links
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



