

Hadoop Tuning Guide
On Bare Metal Ampere Altra Family
Purpose
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
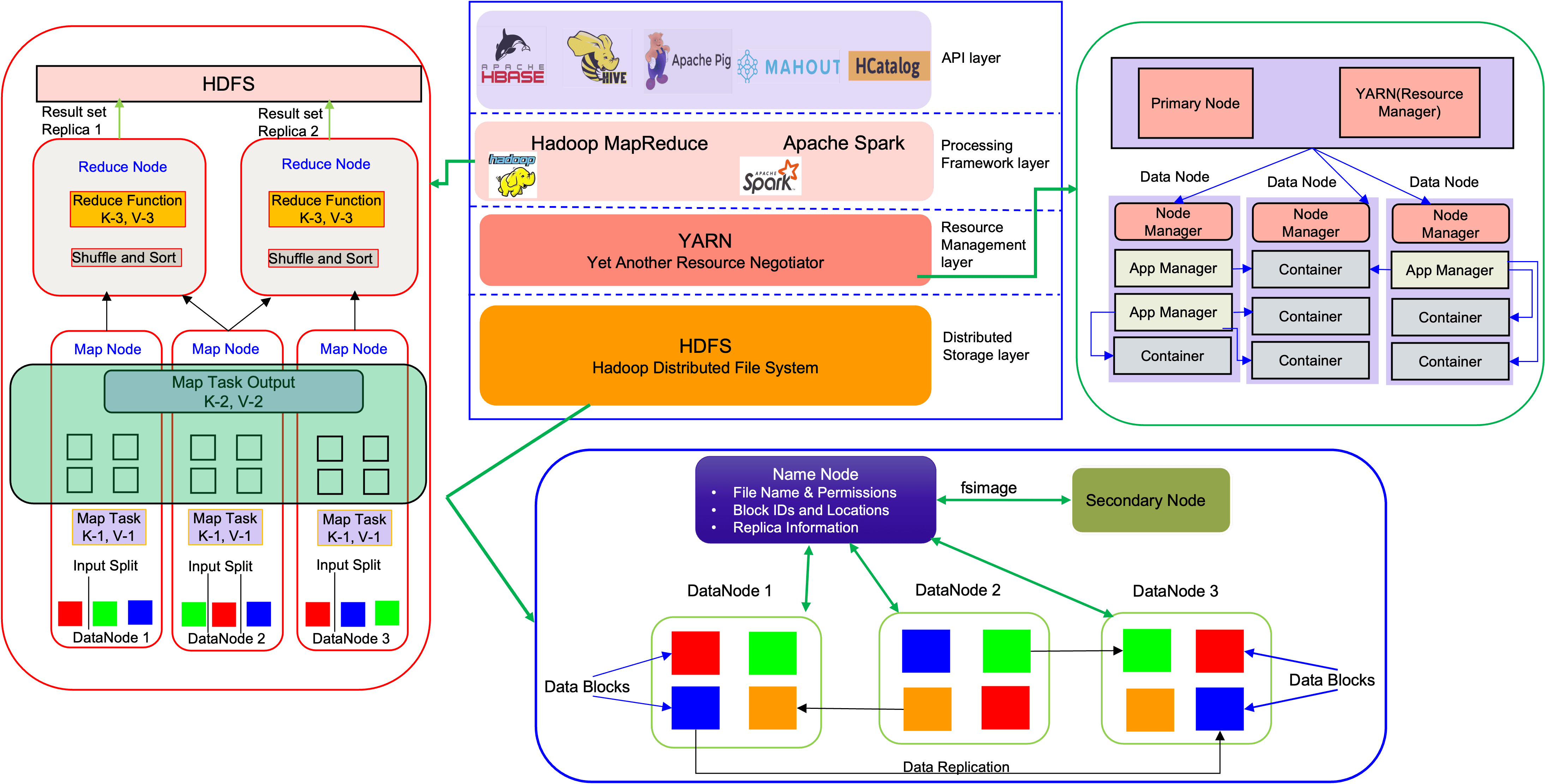
This document was created to provide details on setup and tuning of Hadoop on Ampere Altra family processors.
Hardware and Software Environment
Ampere Altra Max is used in this setup, with 12 x 8TB SATA HDD as the data storage. The detailed hardware and software configurations are listed in Table 1.
| CPU | Ampere Altra Max M128-30 * 1 |
| CPU Freq (GHZ) | 3.0 |
| Cores | 128 |
| Threads | 128 |
| Memory | 32GB * 16 DDR4@3200MHz |
| HDD | 8TB * 12 HGST HUS728T8TAL |
| OS | CentOS 8/CentOS stream 8 above |
| Kernel | 4.18.0-193.28.1.el7 |
| JDK | openjdk-1.8.0.322.b06-1 |
| Hadoop | 3.3.0 |
Table 1: Hadoop HW and SW configuration
Hadoop Setup
1. Install Hadoop Packages
The Apache Hadoop community provides pre-built Hadoop releases for AArch64. They can be downloaded directly from the repository.
Hadoop 3.3.0 is the first release to support ARM architectures. And from version 3.3.1, Hadoop moves to use lz4-java and snappy-java instead of requiring the native libraries of these to be installed on the systems running Hadoop. However, compared to the snappy native library, the snappy java implementation brings about 5% performance penalty.
Hadoop 3.3.0 is selected for this setup.
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/hadoop-3.3.0-aarch64.tar.gz tar zxvf hadoop-3.3.0-aarch64.tar.gz
2. Install Java
On Centos, openjdk v1.8, can be installed using yum repository.
yum install java-1.8.0-openjdk export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
3. Setup passphraseless ssh access
SSH setup is required to do different operations on slave such as starting, stopping distributed daemons.
If you cannot ssh to localhost without a passphrase, execute the following commands to set up a passphrashless ssh access.
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
4. Hadoop Configuration
The Hadoop configurations are mainly in these config files: hadoop-env.sh, core-site.xml, hdfs-site.xml and mapreduce-site.xml.
Setup environment of Java, Hadoop home directory and users in Hadoop-env.sh. Hadoop home directory is the one uncompressed in step one. Here, simply use a root account. In product setup accounts need to follow a security policy. Contents of Hadoop-env.sh:
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::") export HADOOP_HOME=<path of Hadoop package uncompressed> export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
In core-site.xml, the name of the default file system and base for other temporary directories need to be configured. The HDFS daemons will use this property to determine the host and port for the HDFS namenode. Temporary directory should not be missed after node reboot. Contents of the core-site.xml:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/data2/tmp </value> </property> </configuration>
In hdfs-site.xml, replication number, default block size for new files, path of name table(fsimage) and data need be configured. The block size can impact split file size and how many map tasks are required. If the path of name table is a comma-delimited list of directories, then the name table is replicated in all directories for redundancy. To reduce IO, there just needs to be one different disk. If path of data block is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices. Contents of hdfs-site.xml:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.blocksize</name> <value>1g </value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/data3/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <!-- one disk one dir --> <value>file:/data1/data,file:/data2/data,…file:/data12/data</value> </property> </configuration>
In mapreduce-site.xml, the runtime framework for executing MapReduce jobs, environment of map and reduce, history server can be configured. Here yarn is used to schedule jobs. The history server can be accessed via port 19888. Below are the contents of mapreduce-site.xml:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>localhost:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>localhost:19888</value> </property> </configuration>
In yarn-site.xml, pseudo-distributed mode also needs configure yarn.nodemanager.aux-services property to mapreduce_shuffle and local dirs. Auxiliary service response to application start and stop events. Local dirs is a list of directories to store localized files, typically on different devices. Contents of yarn-site.xml:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <!-- one disk one dir --> <value>file:/data1/yarn/local,…file:/data12/yarn/local</value> </property> </configuration>
5. Run Hadoop
The following instructions are to start Hadoop daemons. Namenode is the node in the Hadoop Distributed File System which keeps track of all the data stored in the Datanode. Namenode has metadata related to the data stored on the Datanodes and has information related to the location of the data stored. So, when you run the hadoop namenode -format command, all the information is deleted from the namenode, which means that the system does not know where the data is stored, hence losing all data stored in the Hadoop File System.
- Format the filesystem:
# bin/hdfs namenode -format
- Start NameNode daemon and DataNode daemon:
# sbin/start-dfs.sh
- Start ResourceManager daemon and NodeManager daemon:
# sbin/start-yarn.sh
- Browse the web interface for the NameNode; by default, it is available at:
http://localhost:9870/
- Or access CLI interface at:
# bin/hdfs dfs -ls / Found 1 items drwx------ - root supergroup 0 2022-09-13 21:28 /tmp # jps 77771 NameNode 78091 DataNode 82939 Jps 78636 SecondaryNameNode 80300 ResourceManager 80622 NodeManager
- When you’re done, stop the daemons
# sbin/stop-dfs.ls # sbin/stop-yarn.ls
Tuning for Hadoop
1. BIOS and Kernel configuration
Check and adapt the BIOS setting of the Altra/Altra Max System:
- Advanced->ACPI Settings->Enable Max Performance
- Chipset->CPU Configuration->ANC mode->Monolithic(default)
- Chipset->Memory Configuration->Memory Speed 3200MT/s
- SLC policy->Chipset->CPU Configuration->SLC Replacement Policy->Enhanced Least Recently Used
Or reset the BIOS configuration to restore default setting.
2. CPU/Memory/Disk Benchmark
Before deploying and running Hadoop, make sure all the systems in the cluster are at good health status. Using tools like stress-ng, multiload, stream, fio to check CPU/Memory/Disk or asking Ampere support for Ampere Health Advisor (AHA) for platform health checking.
3. CPU Governor Mode
Set the frequency governor to performance mode:
# cpupower frequency-set --governor performance
On Centos/RHEL, use tuned-adm instead of cpupower command:
# tuned-adm profile throughput-performance # tuned-adm active Current active profile: throughput-performance # cpupower frequency-info analyzing CPU 0: driver: cppc_cpufreq CPUs which run at the same hardware frequency: 0 CPUs which need to have their frequency coordinated by software: 0 maximum transition latency: cannot determine or is not supported. hardware limits: 1000 MHz - 2.80 GHz avaialable cpufreq governors: conservative ondemand userspace powersave performance current policy: frequency should be within 2.00 GHz and 2.80 GHz. The governor "performance" may decide which speed to use within this range. current CPU frequency 2.80 GHz (asserted by call to hardware)
4. File System
Ext4 or XFS can be used as the filesystem. The noatime and nodiratime option can be added for mount options. And it is recommended not to use LVM and RAID on DataNode.
For SATA disk, the better scheduler option is deadline; For NVME disk, noop is better:
# cat /sys/block/sdX/queue/scheduler [mq-deadline] kyber bfq none
Queue depth and number of requests allowed can be adjusted as need to optimize disk IO performance:
# cat /sys/block/sdb/queue/nr_requests 256 # cat /sys/block/sdb/device/queue_depth 32
Increase system limits using ulimit command or modify /etc/security/limits.conf:
# ulimit -u 131072 # ulimit -n 522627
5. Memory
Reducing the value for swappiness reduces the likelihood that the Linux kernel will push application memory from memory into swap space. Virtual Memory Ratios that are too small force frequent IO operations, and those too large to leave too much data stored in volatile memory. Optimizing this ration is a careful balance between optimizing IO operations and reducing risk of data loss. Set these in /etc/sysctl.conf:
vm.swappiness=0 vm.dirty_background_ratio = 10 vm.dirty_ratio = 40
Disable transparent hugepages. Transparent Huge Pages (THP) is a Linux memory management system that reduces the overhead of Translation Lookaside Buffer (TLB) lookups on machines with large amounts of memory by using larger memory pages. However, the THP feature is known to perform poorly in Hadoop cluster and results in excessively high CPU utilization:
# echo never > /sys/kernel/mm/transparent_hugepage/defrag # echo never > /sys/kernel/mm/transparent_hugepage/enabledsbin/stop-yarn.sh
6. Tuning the Number of Mapper or Reducer Tasks
As we saw in the Hadoop architecture picture, an input split is a chunk of input that is processed by a single map. Each map processes a single split. Each split is divided into records, and the map processes each record — a key-value pair — in turn. With default settings, the split size is dfs.blocksize in core-site.xml. So, by default: Number of maps = size of input file / dfs.blocksize
For example, how many maps of 1TB size input file? It is 1,000. The maximum number of simultaneous map tasks per job can be changed in mapred-site.xml, as shown in the configuration below. There is no limit if this value is 0 or negative. Generally, one mapper should get 1 to 1.5 cores. Every map task usually takes 40 seconds to complete execution:
mapreduce.job.running.map.limit=128 -yarn.sh mapreduce.map.cpu.vcore=1
The number of reducers is dependent on IO, more reducers generate more small files, this will impact Namenode; less reducers generate less larger files, it may trigger OOM:
mapreduce.job.reduces=64 mapreduce.job.running.reduce.limit=64 mapreduce.reduce.cpu.vcore=1
More cores of CPU can benefit task, adjust max cores for one task in yarn-site.xml:
yarn.scheduler.minimum-allocation-vcores=1 yarn.scheduler.maximum-allocation-vcores=16 #Automaticall determined from hardware yarn.nodemanager.resource.cpu-vcores=-1
7. Tuning Java
Different JDK versions and sources may cause performance gaps on Java workloads. Please refer to this guide for JDK selection.
Over-allocated heap size and/or improperly configured GC can result in longer full GC runs (during which all other threads in the JVM are paused), badly affecting overall application throughput and ultimately your cluster performance and SLA. Too small heap allocation can cause the JVM to crash due to OOM. Inside mapred-site.xml:
mapreduce.map.java.opts=-Xmx1536m mapreduce.reduce.java.opts=-Xmx3072m
And Use default GC of JDK1.8 or Parallel GC for JDK 11.
8. Minimizing The Disk IO
Disk IO is one of the major performance bottlenecks. One useful method that helps minimize disk is compress output. Inside mapred-site.xml:
mapreduce.map.output.compress=true mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec mapreduce.output.fileoutputformat.compress=ture mapreduce.output.fileoutputformat.compress.type=BLOCK mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
Use native snappy library to compress output file, this can deduce IO. Performance of native snappy library is better than snapyy-java. Hadoop v3.3.0 is suggested since in Hadoop v3.3.1 snapy-java is introduced. Refer to link: https://archive.apache.org/dist/hadoop/common/hadoop-3.3.1/RELEASENOTES.md
Check whether all native library installed:
# hadoop checknative -a
Summary
Hadoop is already supported by the community on aarch64. Ampere Altra family processors not only provide consistent and predictable performance for big data workloads, but also have much lower power consumption over legacy x86 processors.
Ampere Altra family processors are designed to deliver exceptional performance for cloud-native applications. They do so by using an innovative architectural design, operating at consistent frequencies, and using single-threaded cores that make applications more resistant to noisy neighbor issues. This allows workloads to run in a predictable manner with minimal variance under increasing loads. The processors are also designed to deliver exceptional energy efficiency. This translates to industry leading performance/watt capabilities and a smaller carbon footprint.
Please visit the Hadoop workload brief for more performance data: https://solutions.amperecomputing.com/briefs/hadoop-workload-brief
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



