

Diagnosing and Fixing a Page Fault Performance Issue with Arm64 Atomics
Introduction
While running a synthetic benchmark that pre-warmed the cache, we noticed an abnormal performance impact on Ampere CPUs. Digging deeper, we found that there were many more page faults happening with Ampere CPUs when compared to x86 CPUs. We isolated the issue to the use of certain atomic instructions like ldadd which load a register, add a value to it, and store data in a register in a single instruction. This triggered two “page faults” under certain conditions, even though this is logically an all-or-nothing operation, which is guaranteed to be completed in one step.
In this article, we will summarize how to qualify this kind of problem, how memory management in Linux works in general, explain how an atomic Arm64 instruction can generate multiple page faults, and show how to avoid performance slow-downs related to this behavior.
The Problem
The issue was uncovered by a synthetic benchmark that was testing time to “warm up” cache by executing atomic instructions to add 0 to every member of a buffer. This is not an uncommon technique to ensure that the information we care about is loaded off disk and available in memory when we first need it. For example, OpenJDK used an atomic addition instruction from Java 18 and 22 to pre-touch memory by adding 0 to the first entry in each memory page in the “heap” to ensure that it is loaded in RAM.
Using profiling tools, we were able to profile the warm-up phase of the benchmark on both Ampere and x86 CPUs, and see where the extra time was spent. We then used perf to see that the number of page faults was much higher on Ampere, when compared to x86, using Transparent Huge Pages and memory pre-touch. We were also able to get information on THP from the operating system. After the start-up phase, performance was still impacted on Ampere, and in the /proc/vmstat directory, we were able to see that on Ampere systems, the thp_split_pmd counter, indicating the number of fragmented Huge Pages in memory, was much higher than expected. This indicated that, as part of the warm-up, Transparent Huge Pages were being fragmented, causing a performance issue.
On Ampere and other Arm64 platforms since ARM 8.1-A, atomic instructions can use the Large Systems Extensions (LSE) family of atomic instructions. In Arm architectures before the introduction of LSE, atomic additions worked by using separate instructions to load a value from a register, and to check if the register had changed before saving an updated value (Load-Link/Store Conditional atomics). With LSE, Arm introduced a set of single-instruction atomic operations, including ldadd, which performs a load, add, and store operation. You would expect a single CPU instruction to generate a single page fault. However, because of how these atomic instructions are implemented on Arm64, this single instruction first generates a “read” fault, corresponding to loading the value of the register, and a separate “write” fault, corresponding to the new value being stored. As a result, this causes an excess of page faults.
This is bad for several reasons:
- This is a significant performance hit in regular operation, because page faults, and the required TLB maintenance that comes with them, can significantly affect performance.
- When using Transparent Huge Pages (THP) this will result in huge pages being broken up. When the Huge Page is first referenced, the kernel provisions a single “huge” zero page, but as the memory is written to, this triggers a “Copy-on-Write" in the kernel for each memory page, resulting in individual memory pages being allocated, rather than the contiguous block of memory that you would expect. This means that pre-touching the memory causes 512 page faults for a 2M HugePage and 4k kernel page size, rather than the one that you expect. In addition, because the HugePage is not contiguous in memory, there is start-up impact.
Memory Management – The 10,000ft overview
To explain how atomic instructions can cause multiple page faults, and why this has a performance impact, let’s take a brief detour into how memory management works in a CPU from a very high level.
Operating systems create a virtual memory address space for programs running in user space and manage the mapping of virtual memory addresses to physical memory addresses. In addition, Linux offers a feature called Transparent Huge Pages for userspace programs, which allows those programs to reserve large contiguous blocks of physical memory, and treat that memory as a single page, even though in practice these Huge Pages are made up of many contiguous physical memory pages.
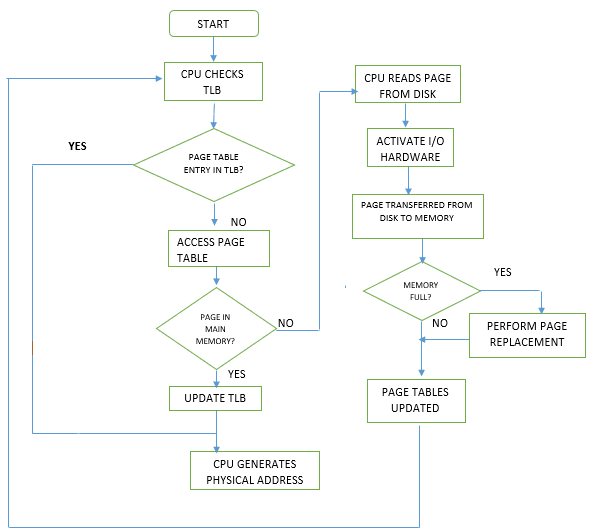 Figure 1. Memory Management
Figure 1. Memory Management
When a virtual memory address is accessed by an application, the operating system first performs a check to see if this virtual memory address is in a physical memory page that is already available in memory. The kernel does this by checking its page table, a collection of mappings from virtual memory addresses to physical memory addresses. The first step in this process is to check the Translation Lookaside Buffer (TLB), which stores a relatively small number of page table entries to accelerate access to the most used memory locations. If the address requested is not in the TLB, the CPU then checks its page table to see if the requested address is already in memory. If it is not, then a page fault is triggered.
There are two types of page faults: a read fault and a write fault. For reads of uninitialized memory, the kernel can avoid accessing physical memory entirely by using a special page called the zero page, which returns zero to all load instructions. When a memory page is written to, this triggers a write fault. A location in physical memory is allocated, the mapping of that address to the virtual memory address of the application in question is stored in the page table, and this mapping is also stored in the TLB for future reference, invalidating the existing TLB entry for the zero page in the process.
But why can this impact performance on Ampere CPUs in certain situations, and what exactly does that have to do with atomic instructions? To understand that let’s dig a little deeper into how LSE atomic instructions work.
Atomic instructions on Arm64 and Page Faults
Atomic instructions are a way to guarantee that a block of code will either execute completely, or not at all. These instructions are necessary because multiple programs or threads can run on the same CPU at the same time. In normal operation, the operating system manages how much of the CPU’s time is allocated to each thread, and which processes run in what order. What this means is that a process or thread can be put into a “wait” state in the middle of a routine, resulting in a context switch as the CPU saves its state for one process, and loads the state of the next process to run.
For example: imagine that we have a program that will run using threads and will be counting something. Now imagine that thread 1 reads the value of the counter, say 20, and adds 1 to it, but before it can write this new value of 21 back to the counter, thread 2 reads the old value 20 from the counter, adds 1 to it, and attempts to write its new value back to the counter. As a result, we have undercounted whatever it is that we were counting. This is the problem that we solve using atomics.
On Arm64, since ARM 8.1-A, Large System Extensions (LSE) atomic instructions are used for this purpose. In a single instruction, we can read the value of a register, modify its value, and store the result. Using LSE instructions, an atomic increment routine can use a single ldadd instruction to load a register and add to it.
This interacts with the memory management subsystem, because this single instruction still triggers two different operations: a load to read the old value, and a store to write the new value. The load operation will cause a “read” page fault, but since the page has not yet been referenced, the kernel will not actually allocate a page in main memory, instead using a special “zero” page to save time. If we now immediately write a value to that register, we trigger a “write” page fault, which allocates some physical memory, associates it with a location in virtual memory, and then stores a value. For a single atomic instruction, we have caused two page faults, each of which has a cost.
In cases where we are using 2M large Transparent Huge Pages, our initial load operation can trigger a read fault which returns a 2M large kernel zero page, but our store operation, triggering a write page fault, only allocates a 4K memory page. If we are pre-warming the full 2M Huge Page, this will trigger a new write fault every 4K, for 512 extra write faults. What is worse is that what should have been a contiguous 2M block of memory has become a non-contiguous collection of 4K pages in physical memory.
Solving the Problem
Addressing this issue really comes down to two things.
First, for memory warm-up, there is an alternative mechanism that can be used to pre-touch memory. The Linux kernel provides a system call: madvise() to allow the application developer to indicate intentions related to memory, and to give advice to the kernel on how the application will use certain sections of memory. This enables the kernel to proactively use appropriate caching or read-ahead techniques to improve performance. In the case of the issue, we discovered while starting the JVM with –XX:+UseTransparentHugePages –CC:+AlwaysPreTouch, which started us on this journey, we updated the behaviour of the JVM to call madvise(addr, len, MADV_POPULATE_WRITE) to indicate to the kernel that we intend to write to this area of memory. This avoids the interaction of atomic instructions and memory warm-up altogether. However, the ability to indicate MADV_POPULATE_WRITE to madvise was only added in Linux kernel 5.14, so for older versions of Linux, this is not an option.
Second, we are working with the Linux kernel community to ensure that when we are using THP, that a write fault on a huge zero page allocates a huge page in memory. While this issue is not yet completely resolved, the Linux kernel community is working on a patch, and we expect the issue to be fixed soon.
For regular pages, the Linux kernel will continue to trigger two page faults with atomic addition instructions, by virtue of how these instructions are implemented in ARM. We believe that atomic “Read-Modify-Write" instructions should only generate one write fault, which would improve performance for these operations. We are still discussing in the kernel community the right way to accomplish this change. In our tests, making such a change halved the number of page faults during a “memory warm-up" benchmark, and reduced the time for the operation by 60% on a virtual machine running on an Ampere Altra CPU.
References
- “Transparent Huge Page support”: https://docs.kernel.org/admin-guide/mm/transhuge.html
- “v5 Patch: mm: Force write fault for atomic RMW instructions”: https://lore.kernel.org/lkml/20240626191830.3819324-1-yang@os.amperecomputing.com/
- “Huge Zero page confusion”: https://lore.kernel.org/linux-mm/1cfae0c0-96a2-4308-9c62-f7a640520242@arm.com/
- “pretouch_memory by atomic-add-0 fragments huge pages unexpectedly”: https://bugs.openjdk.org/browse/JDK-8272807
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



