
Cloud Native Processor Leadership on Microsoft Azure VMs

Recently we wrote about the overwhelming leadership of the Ampere® Altra® family of Cloud Native Processors on popular cloud native workloads. In that blog, we highlighted how Ampere leadership extends well beyond raw performance, showing scalability and significant power efficiency advantages, with Ampere Altra Max Cloud Native Processors consuming half the power of legacy x86 processors under similar peak workload conditions. This kind of advantage is truly disruptive, making the Ampere Altra family the most sustainable processor for modern cloud infrastructure.
In this blog, we take a look at a handful of similar cloud native workloads running on the recently announced Microsoft Azure VMs based on Ampere Altra Cloud Native Processors, which will be generally available on September 1. While the data in our previous blog shows performance and power efficiency on bare metal servers for Ampere Altra Max, most customers worldwide will access Ampere’s groundbreaking Cloud Native Processors first through IaaS services such as the ones offered by Microsoft Azure. Hence, we thought it was a good time to demonstrate the advantages end customers gain by simply renting Ampere Altra-based virtual machine instances in the cloud. The comparisons shown here will focus on raw performance and price-performance, whereas the comparison for bare metal showed raw performance and performance per Watt to highlight the sustainability aspect of using Ampere Cloud Native Processors. The power efficiency advantage is still present when renting a VM on the cloud and translates into the savings you see when renting an Ampere VM from our cloud partners like Microsoft. Lower power costs lead to not only a more sustainable computing infrastructure for our collective good (think lower carbon footprint), but also in the lower costs associated with owning and running these platforms in a scale out infrastructure!
In the cloud, server access is most often provisioned through virtual machines (VMs). The VMs come in a variety of sizes and shapes to accommodate the vast array of applications and use cases in the cloud. VMs also give us a different standard configuration to measure when comparing cloud-based virtual machines instead of the bare metal comparisons we often make in our labs.
Before we get to the data, it is worth highlighting the differences you will and won’t see when comparing performance of VMs in the cloud.
- When testing VM images in the cloud we used a standard size offered by Azure. In this case we most often chose a 16 vCPU instance due mostly to the popularity of these VM sizes in the cloud.
- When provisioning VMs in the cloud it is important to note the differences between vCPUs between different architectures. A legacy x86 VM will have 2 vCPUs per core, whereas an Ampere Altra VM uses single-threaded cores and therefore 1 vCPU per core. That means you have 2X the number of cores on similar-sized VMs when deploying Ampere Altra-based VMs.
- We use equivalent services in storage and networking according to the available Azure service list where applicable.
- For equivalent competitive comparisons we ran a 16 vCPU VM for all data collected and shown in this article. The VMs used are shown in the table below.
| VM | vCPUs | Cores | Processor |
|---|---|---|---|
| D16ps v5 | 16 | 16 | Ampere Altra |
| D16s v5 | 16 | 8 | Intel Ice Lake |
| D16as v5 | 16 | 8 | AMD Milan |
In addition to raw performance data collected for each workload, we have also used the published on-demand pricing information (pay-as-you-go) to calculate the total value of running a particular workload on an Azure VM in monetary terms. The pricing can be found on the Azure website and, as noted, is subject to change. The price-performance value is [the combined value of running the workload on equivalent VM sizes with equivalent services based on the performance advantage measured] * [the cost advantage for each of the comparable VMs]. Now on to the data. The workloads shown are popular cloud native workloads run in real-world service installations and are therefore highly representative of what many end customers deploy in the public cloud infrastructure.
Web Services
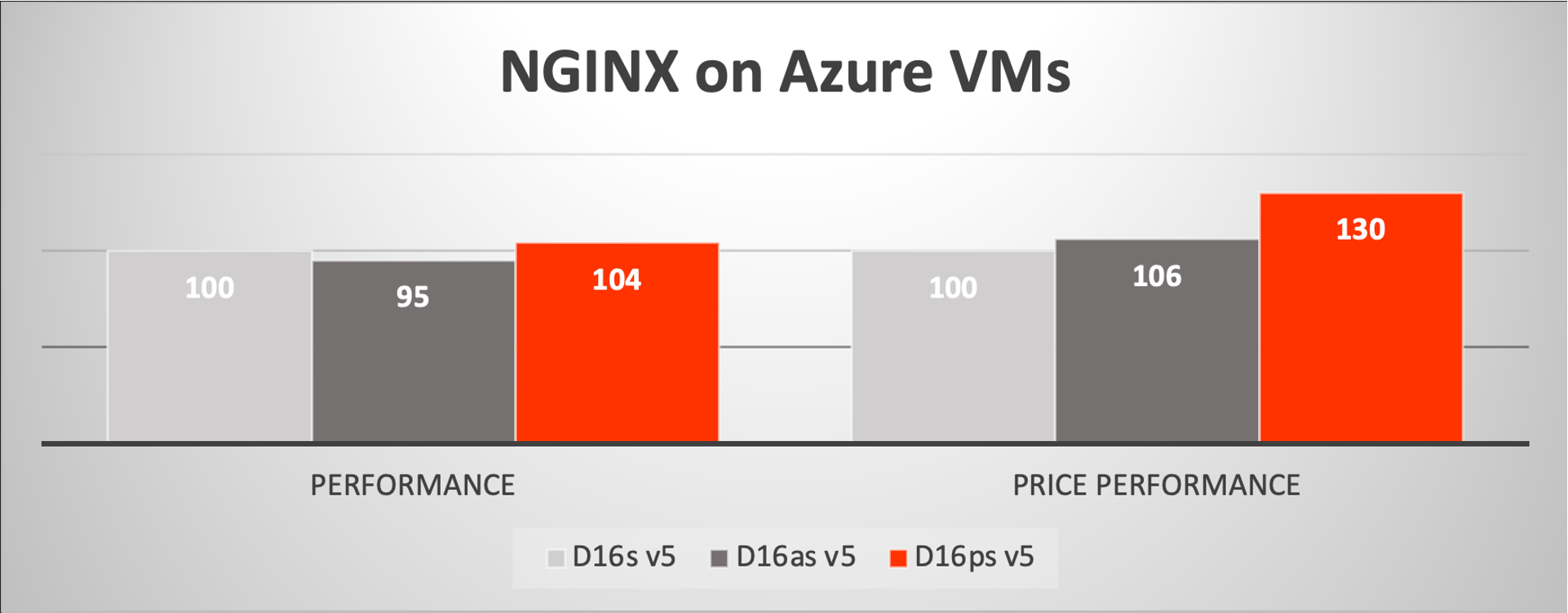
First, we look at NGINX, a very commonly deployed HTTP web server. We have shown how NGINX performance at the socket level outperforms the legacy x86 ecosystem by wide margins in both raw performance and power efficiency. Translated to the VM world with 16 vCPUs, we see that the performance advantage combined with the price advantage (related to the power efficiency as noted previously), shows up to 30% value over the Dsv5 (Intel) and Dasv5 (AMD) VMs. Note that the comparisons for performance and price-performance are relative to the Intel DSv5 VM except where otherwise noted.
In-Memory Caching
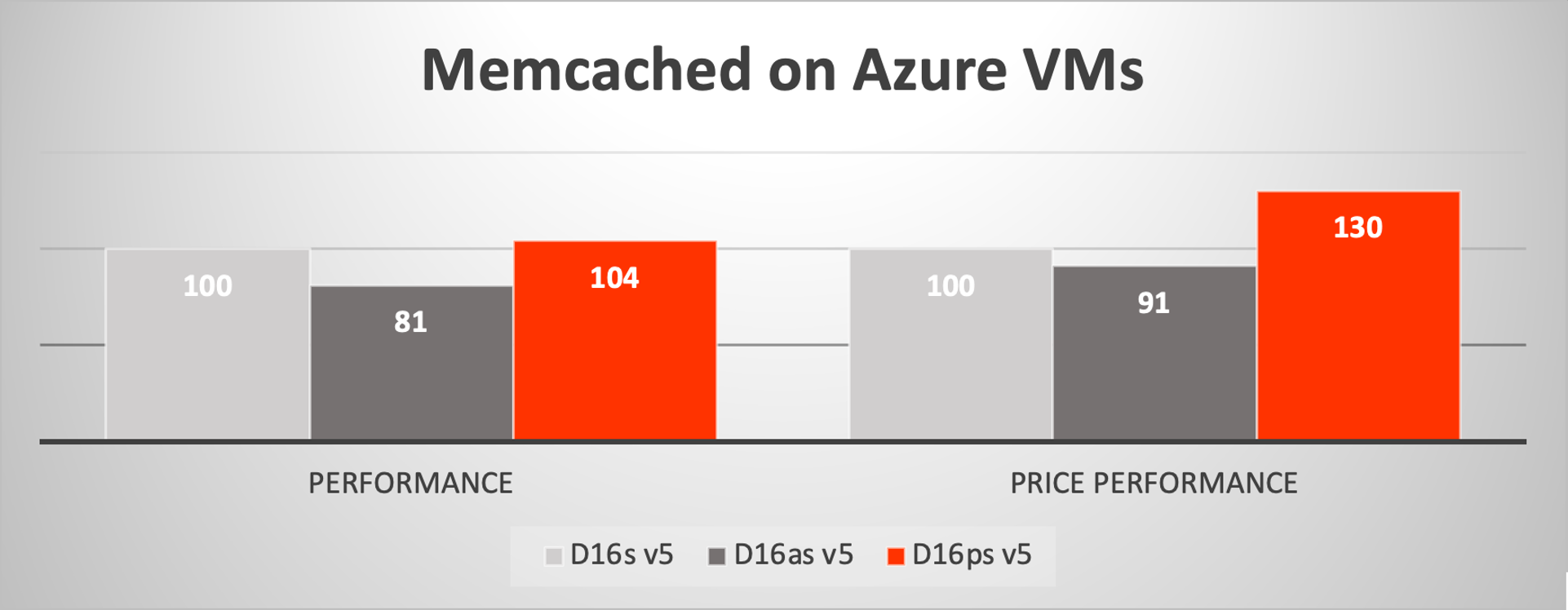
For Memcached, a widely deployed in-memory key-value store, we see a similar pattern emerge. For in-memory caches, VMs of 8 to 16 vCPUs within the range we tested are commonly deployed, making the overall performance value we see very compelling for workloads like microservices that incorporate caching layers. With these tests, we measured 30% higher price-performance value over the Intel Dsv5 VM and 43% better than the AMD Dasv5 VM.
Video Services
Video encoding is considered a bulk application for many cloud services, making it a high volume and highly optimized workload. The Arm ecosystem is gaining significant ground in algorithm optimization and codec efficiencies.
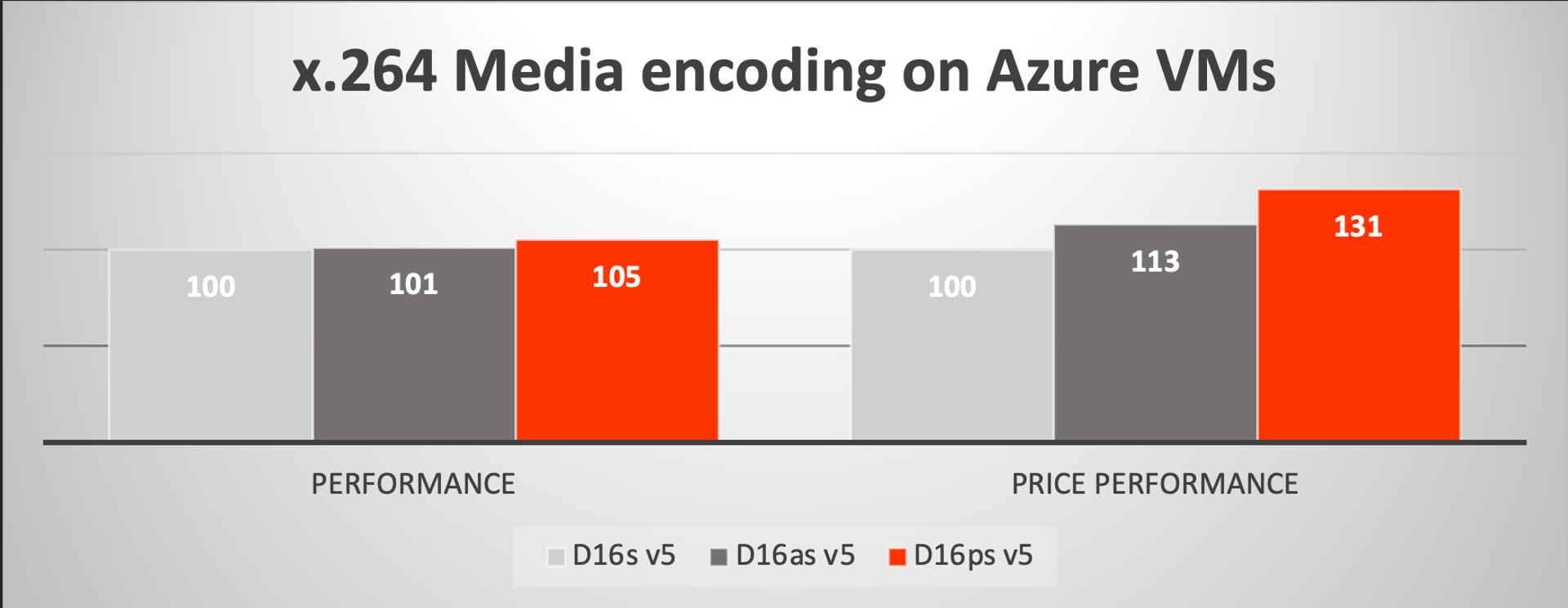
In this case, we ran media encoding on vBench using the x.264 encoding library in two scenarios: Video Upload and Video on Demand (VoD). These two scenarios tested very similarly in our VMs so we are showing the data for the upload scenario, which uses a single pass transcoding without degrading the input video quality, representing the initial upload encoding to a video service, requiring speed and quality. These tests showed roughly equivalent performance for the 16 vCPU Ampere and legacy x86 VMs, but up to 30% better price-performance based on the published pricing.
AI Inference
Finally, we look at AI inference benchmarks. Machine learning is increasingly consuming more cycles in the cloud as AI becomes an integral component of many web and standalone services. Ampere has compiled an easy-to-use stack to accelerate typical AI workloads for Computer Vision, Natural Language Processing, and recommendation engine use cases. Ampere AI combines an acceleration layer with common open-source AI frameworks such as TensorFlow, PyTorch, and ONNX. The beauty of Ampere AI is that users are free to choose the models of their choice compatible with their chosen framework and run in an optimized flow for Ampere Cloud Native Processors. No changes are necessary to the models to accomplish this task and users can take advantage of unique features in the Ampere processors such as fp16, a data format that yields roughly 2x performance over the common fp32 format with little to no loss in accuracy. You can find the free images for the common frameworks mentioned above on the Ampere solutions website and soon on the Azure marketplace.
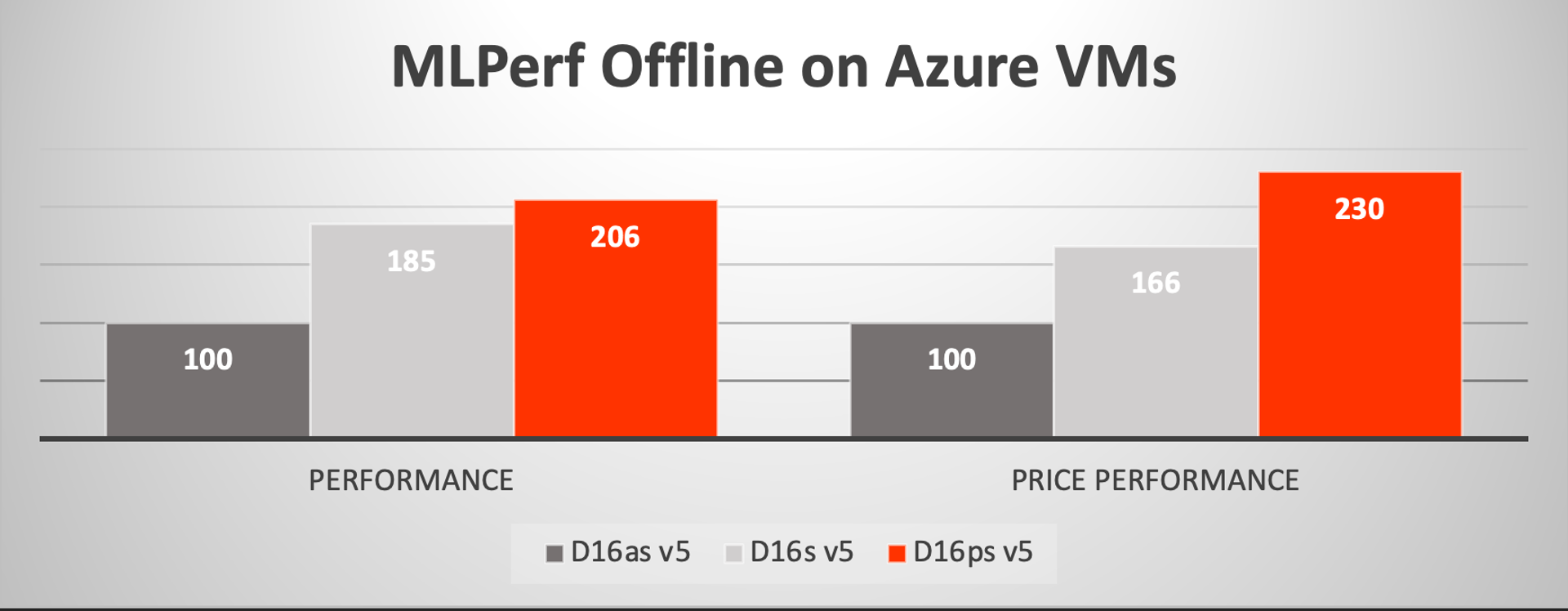
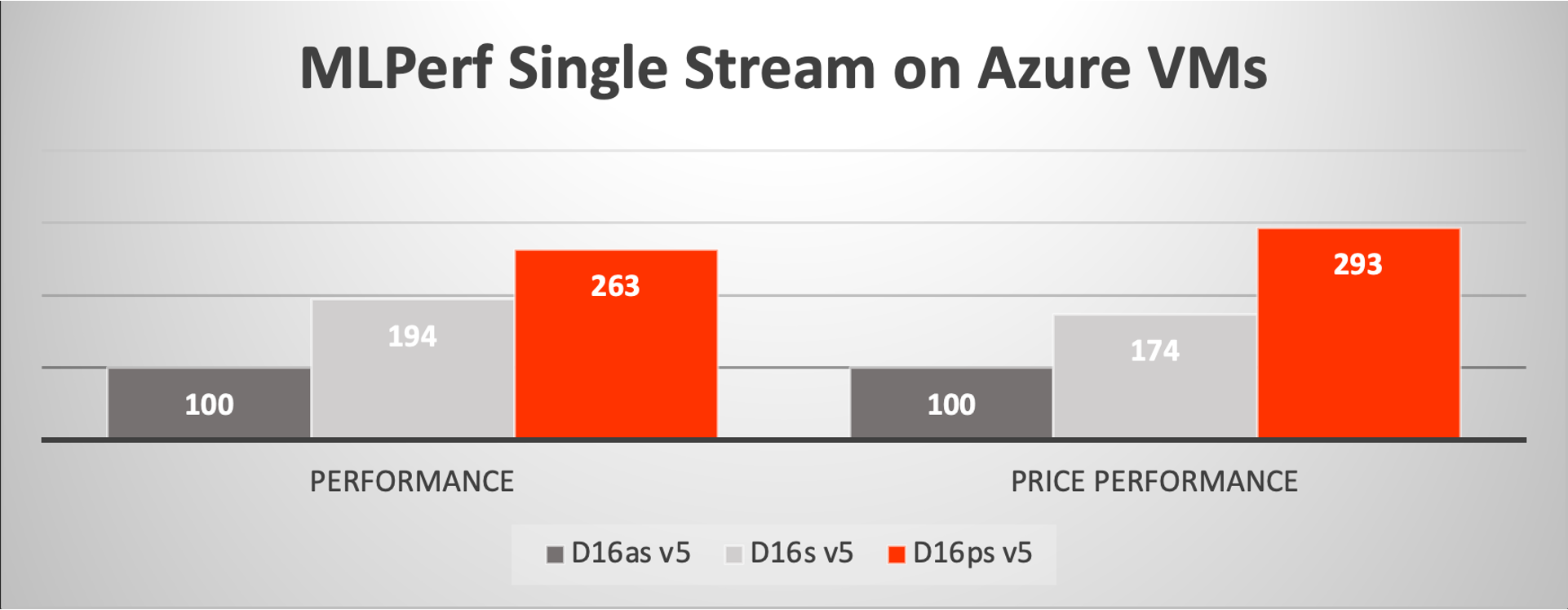
Using a common set of benchmarks, we’ve compared AI inference performance with MLPerf Resnet50 v1.5 in single stream and offline scenarios. These scenarios represent the most common use cases for image classification in the data center reflecting both latency sensitive (one frame or image at a time) and bulk throughput (as many as you can return in parallel) operations respectively. Both these benchmarks were run using TensorFlow 2.7 with Ampere AI container images on the D16ps v5 VM using the fp16 data format and are compared to the legacy x86 run using TensorFlow 2.7 with DNNL using fp32 data formats. Ampere testing shows that accuracies for these models using the stated formats are nearly exact. The comparison shows that Ampere AI technology yields over 2x performance gain over the legacy x86 VMs and even more compelling 2-3x price-performance value over the legacy x86 machines!
Conclusion
Whether deploying a new web service or looking for ways to optimize existing services in AI, video encoding, data management and analytics, cloud developers now have access to a low cost and high-performance alternative to the legacy infrastructure widely available today. In the past, lower price has meant lower performance. Not anymore! Microsoft Azure customers no longer need to make such tradeoffs; they can get higher performance while lowering their costs. At the same time, it is comforting to know that by making this kind of choice, customers are lowering their carbon footprint while delivering significant cost savings with no performance compromise! Sound too good to be true? Try it for yourself and experience the amazing results and innovation.
Ampere has a collection of programs that allows free-tier access to our customers, developers, and partners. These programs offer access to Ampere’s world-class Cloud-Native processing power through:
- Bare-metal instances hosted by Equinix
- Ampere in-house platforms with GPU
- Access to specialized clusters co-developed with partners
- Access to pre-production hardware
- Links to our partner free-tier programs (e.g. OCI free tier
Find the system best suited for your workload needs by visiting our Where To Try page on the Ampere Solutions Portal.
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



