
百度 BCC GR1 实例 – AI 推理加速

今天 AI 推理已经在数字应用中被广泛使用,对于大规模 AI 模型或者对性能很高的场景,多数是利用 GPU 或者专用芯片来实现。但是对众多诸如 Web 应用,或者像数据治理这类独立数据服务系统来说,采用 GPU 平台并非是成本效益最好的选择。随着其工作负载动态波动,GPU 的工作量很少饱和,GPU 的算力并不总是被充分利用,很难实现随着实际业务量的变化进行灵活的扩展。这时,采用 CPU 做 AI 推理可以依靠最为常见,配置丰富的标准型云服务器就能满足业务需求。除了更低的云服务器采购成本,用户将拥有更好的可控性,不依赖第三方硬件,涉及操作系统、驱动程序、运行时的软件复杂性较低,而且更易于扩展并与其他软件堆栈和微服务集成。
百度智能云新型 BCC 实例产品 GR1 不同于其他云服务器,GR1 所搭载的Ampere® Altra® 云原生处理器基于 Arm 指令集架构,采用单线程内核设计,云实例的每一个 vCPU 都是独立的物理核,独享 ALU(逻辑计算单元),缓存等关键物理资源,可以实现稳定可预测的性能。
GR1 实例所使用的 Ampere® Altra® 云原生处理器也为 AI 工作负载提供卓越的性能和能效,其原生支持 FP16 数据格式。与 FP32 模型相比,FP16 提供高达 2 倍的性能加速,将 FP32 训练的网络量化为 FP16 很简单,不会导致明显的精度损失。同时,GR1 实例无需修改即可在 TensorFlow、PyTorch 或 ONNX 框架上开发和运行 AI 推理的工作负载。目前,Ampere® 优化的 TensorFlow、Pytorch 和 ONNX 的镜像已经在百度智能云的公共服务集成镜像中免费提供,您可在创建 GR1 实例时按需进行选择。
在本示例中,我们将演示如何在基于百度智能云的 GR1 实例上部署 Ampere® AI 优化的 PyTorch 框架软件栈,并使用 PyTorch 对 ResNet50 v1.5 分类模型进行测试和评估。
创建 GR1 实例
百度智能云提供在数个百度智能云地区和可用区创建和使用基于 GR1 实例:北京(D 区域, E 区域), 广州(C 区域)和苏州(D 区域)。
在本文中,我们将在百度智能云创建一个 16 vCPU 及 64GB 内存 bcc.gr1.c16m64 规格的 GR1 实例。
首先,从控制台进入“云服务器 BCC”服务页面,点击“创建实例”按钮:

在云服务器创建导览页面中,选择在广州可用区 C 创建 GR1 实例。
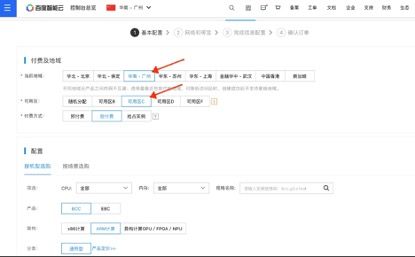
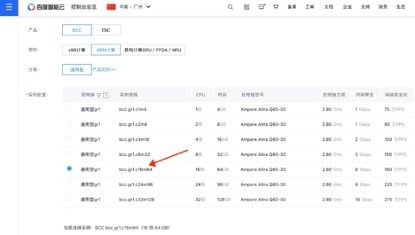
在实例配置选项中,选择 bcc.gr1.c16m64 实例规格:
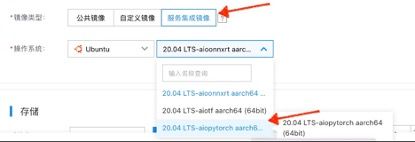
同时为 GR1 实例选择服务集成镜像中的 AIO PyTorch 镜像:
在随后的配置项中完成剩余的存储及网络配置并确认提交云主机配置信息即可开通 GR1 云主机实例。
连接 GR1 实例
在云主机 BCC 控制台确认刚创建的 GR1 主机处于“运行中”状态,即可通过 ssh 连接至部署 Ampere AI 镜像的 GR1 主机:
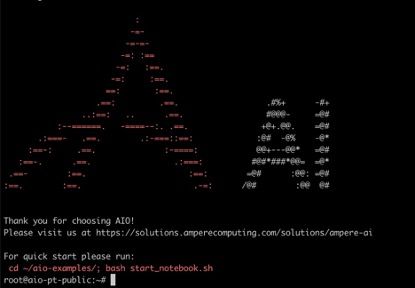
登录后在终端看到 AIO Logo,说明 Ampere® AI 镜像已成功在 GR1 实例上部署,并且我们可以通过 Ampere® AI 镜像集成的示例代码测试评估 Ampere® AI 框架如 PyTorch 在 GR1 上的性能。
测试 AIO 示例
在本示例中,我们将测试和评估 AIO 的图像分类性能。我们使用最常用的 ResNet50 v1.5 图像分类模型进行测试。Ampere PyTorch 优化镜像提供 Jupyter Notebook 示例和 Python CLI 脚本两种运行方式。
使用 Jupyter Notebook 运行
在 GR1 实例上设置 AIO_NUM_THREADS 和 OMP_NUM_TREAD 环境变量为 16, 并打开 FP16 自动隐式模式,该模式允许框架尽可能的尝试将 FP32 模型作为 FP16 运行,并可以在几乎不影响模型精度的前提下大幅提升性能:
export AIO_NUM_THREADS=16; export OMP_NUM_TREADS=16; export AIO_IMPLICIT_FP16_TRANSFORM_FILTER=".*"cd /aio-examples/运行 start_notebook.sh bash 脚本启动 Jupyter Notebook:
bash start_notebook.sh
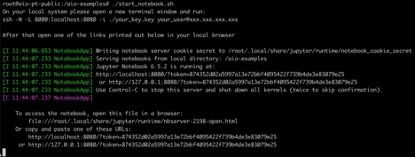
同时在您的本地电脑上运行如下命令开启 SSH 端口转发:
ssh -N -L 8080:localhost:8080 -I <ssh_key> your_user@xxx.xxx.xxx.xxx随后在本地电脑浏览器中访问上图中 Jupyter Notebook 启动过程中最后给出的 localhost URL, 即可打开 Jupyter Notebook 可视化页面:
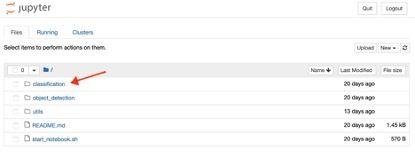
进入 classification 图像分类目录,点击 examples.ipynb:
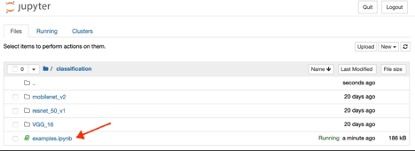
即可打开 classification 示例页面,点击 cell->Run All 执行示例:
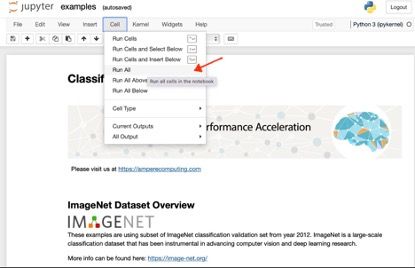
从运行结果可以看到使用 AIO 后,图像分类的推理速度约提升了 3 倍多:
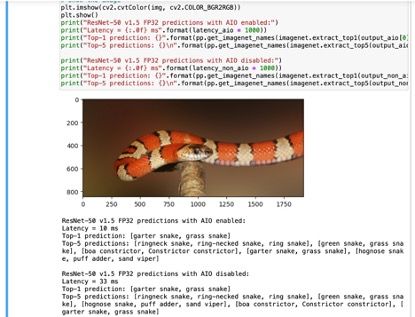
除了图像分类之外,aio-example 也提供了的目标检测的示例。在 Jupyter Notebook 主页进入 object_detection 目录执行同样的操作即可进行测试评估。
使用 Python 脚本运行
同样针对测试实例配置设置环境变量,并进入 GR1 实例上的 aio-example 示例目录。这里我们将 AIO_NUM_THREADS 和 OMP_NUM_THREADS 设置为 16, 并同样打开自动隐式 FP16 模式:
export AIO_NUM_THREADS=16; export OMP_NUM_TREADS=16; export AIO_IMPLICIT_FP16_TRANSFORM_FILTER=".*"cd /aio-examples/随后进入 resnet_50_v15 分类模型目录进行测试:
cd classification/resnet_50_v1numactl --physcpubind=0-15 python3 run.py -p fp32并可在终端得到如下运行结果:
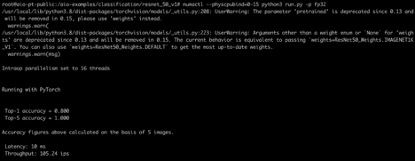
可以看到使用 AIO 后,c16m64 规格的 GR1 实例使用 ResNet50 v1.5 图像分类模型,在 FP32 双精度下的输出可达 105 ips。
与 x86 实例的横向对比
我们分别在百度智能云上创建了同样为 16 vCPU 和 64GB 内存,基于 Icelake 的 bcc.g5.c16m64 和基于 Milan 的 bcc.ga2.c16m64 实例。在 bcc.g5.c16m64 上我们使用 Intel 优化的 intel_extension_for_pytorch-1.13.0 框架, 在 bcc.ga2.c16m64 上使用 AMD 优化的 ZenDNN_v3.3 框架并运行相同的 aio-example ResNet50 v1.5 图像分类模型。我们取十次运行的平均值,得到如下结果:
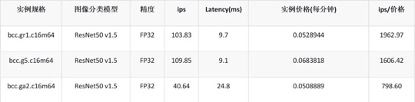
从对比结果我们可以看到,GR1 实例的性能和基于 Icelake 的 G5 实例的 ResNet50 v1.5 图像分类模型性能接近(95%),而比基于 Milan 的 GA2 实例的图像分类推理性能高出约 155%。 若考虑到实例的价格,在相同的单位价格下 GR1 可以提供比 G5 实例高约 22%,比 GA2 实例高约 146% 的图像分类推理性能。
总结
正如本示例所展示的,对于主流的 AI 推理场景,如 ResNet50 v1.5 图像分类模型等。采用 Ampere® Altra® 处理器的 GR1 实例可提供比主流 x86 实例多达 146% 的性价比优势,您可以通过部署百度云市场中的 Ampere® AI 服务集成镜像亲自体验。
敬请访问 Ampere® AI 解决方案网站https://amperecomputing.com/zh-CN/solutions/ampere-ai
进一步了解 Ampere® Altra® 处理器家族在 AI 场景下的强大之处。
References: 1. https://solutions.amperecomputing.com/solutions/ampere-ai 2. https://baijiahao.baidu.com/s?id=1751709038217955693 3. https://mp.weixin.qq.com/s/1VTSYECcgj5jaUlmBdm2uw
Ampere Computing
4655 Great America Parkway
Suite 601 Santa Clara, CA 95054

