
基于BCC GR1实例部署 Elastic Stack

简介
百度智能云正式发布了新型BCC实例产品 GR1。不同于其他云服务器,GR1所搭载的Ampere® Altra® 云原生处理器基于Arm指令集架构,采用单线程内核设计,云实例的每一个vCPU都是独立的物理核,独享ALU(逻辑计算单元),缓存等关键物理资源,可以实现稳定可预测的性能。
目前GR1实例已经已支持CentOS7.9、CentOS7.6、Ubuntu22.04、Ubuntu20.04等常用Linux公共镜像。GR1实例产品主要面向常见的云原生应用负载,如开源数据库、Java应用程序、视频编解码、AI推理(数据治理)、大数据分析、DevOps、Web服务应用等。为了让客户更轻松地部署云原生的工作负载,作为百度智能云容器化工作负载的关键基础设施Cloud Container Engine(CCE) 目前已提供对GR1实例的支持。
在本示例中,我们将演示如何在基于百度智能云GR1实例的 CCE集群上部署 ELK 软件栈,以从 Kubernetes 集群内的 Pod 收集日志。
传统的ELK软件栈由Elasticsearch, Logstash, 和Kibana组成。从2015年起,轻量级的数据传输器Beats家族开始非正式的成为ELK中的一个组件。 ELK 软件栈为开发人员提供了端到端的能力来聚合应用程序和系统日志、分析这些日志以及可视化洞察以进行监控、故障排除和分析。
准备工作
在开始前, 我们假设您已做了如下准备 o 您已经有一个百度智能云账户 o 您的百度智能云账户具有创建Arm Kubernetes CCE容器引擎的权限。 o 您本地操作终端已安装kubectl工具。
如果上列准备已经就绪,我们就可以进行下个步骤 —— 在部署ELK之前,先创建基于百度GR1实例的Arm架构容器引擎。
首先创建基于GR1的容器引擎
除了在 BCC上发布 Arm 实例外,百度智能云还提供使用基于 Ampere Altra 的 GR1 实例在 CCE上运行容器化的Arm 工作负载。数个百度智能云地区和可用区现在可使用于基于 GR1实例创建 的CCE集群:北京(D区域, E区域), 广州(C区域)和苏州(D区域)。
在本文中,我们将在百度智能云的北京可用区D创建一个由3个master节点,以及3个worker节点组成的集群。 首先,从控制台进入CCE容器引擎服务页面,点击“创建集群”按钮:
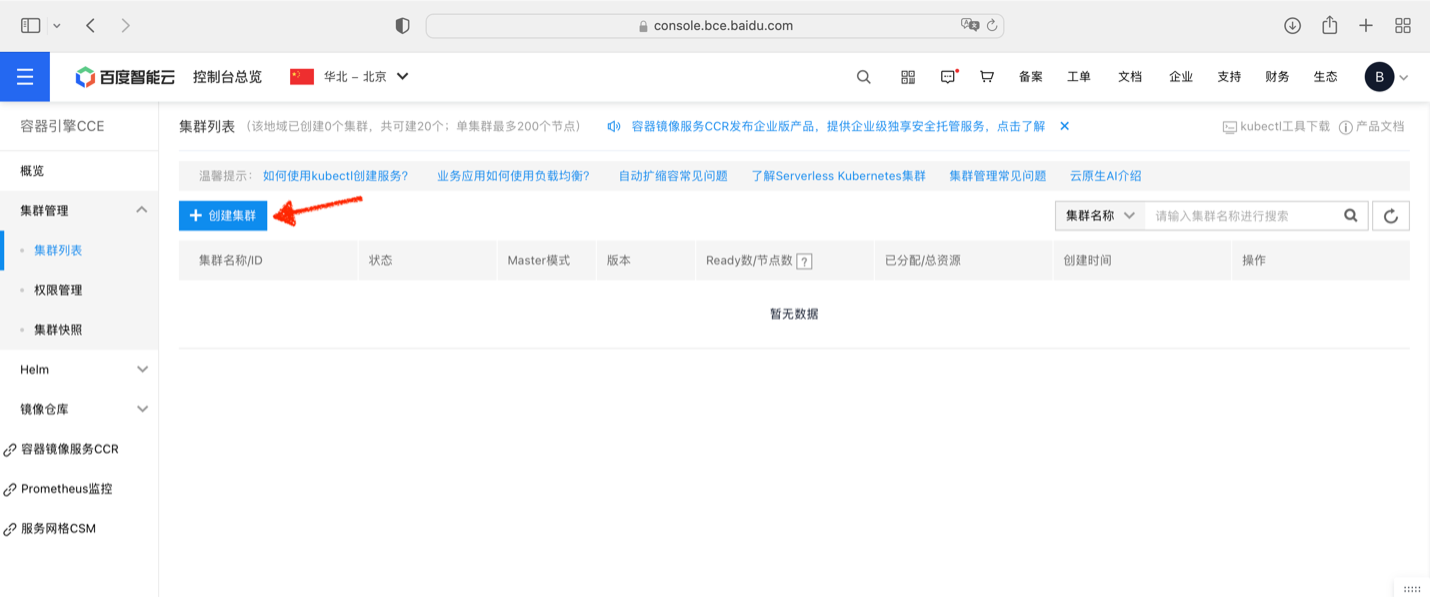
在集群创建导览页面中,选择创建 Arm Kubernetes集群。
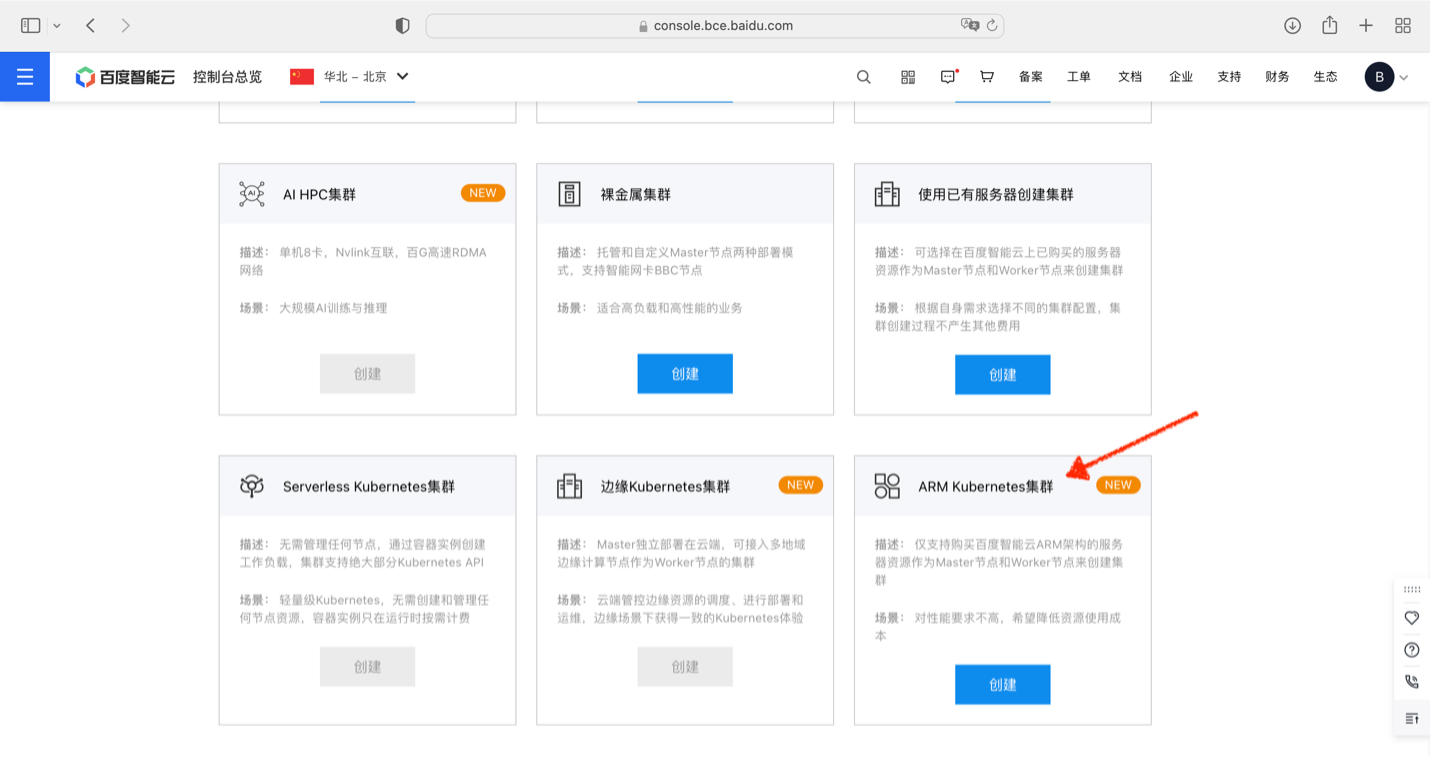
按集群创建向导选择3副本Master配置:
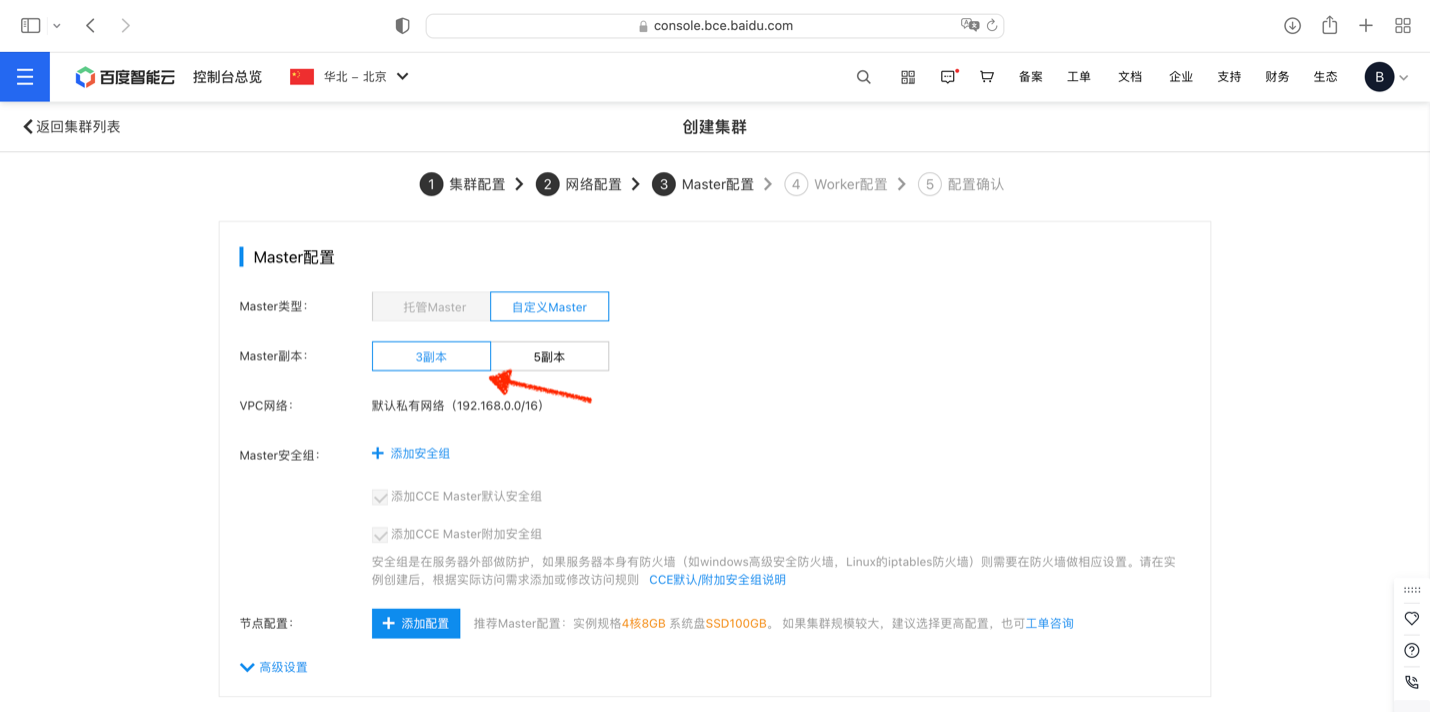
并添加3台GR1.c4m16实例作为Master节点:
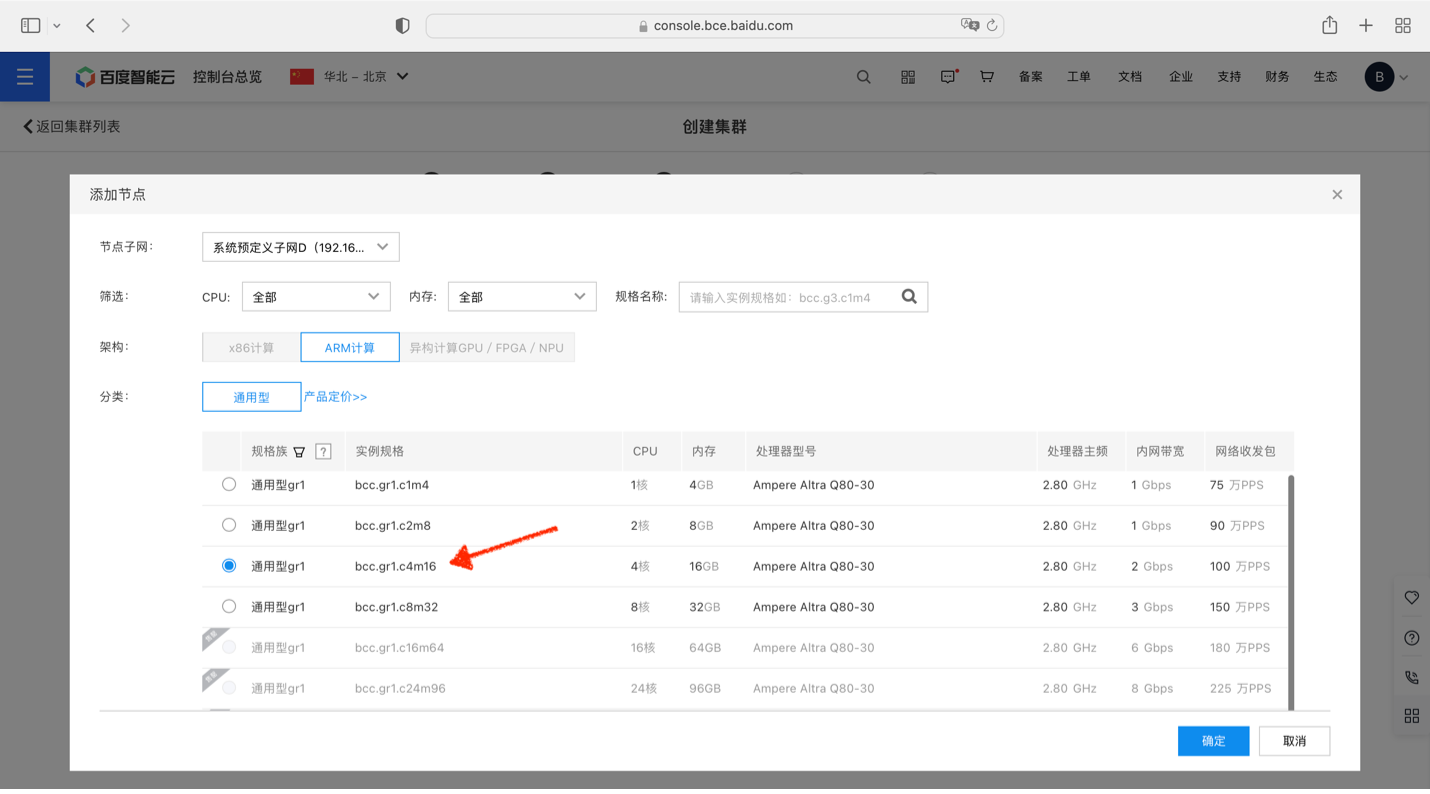
类似的,在添加Worker节点的步骤中,选择添加3台GR1.c8m32实例作为Worker节点:
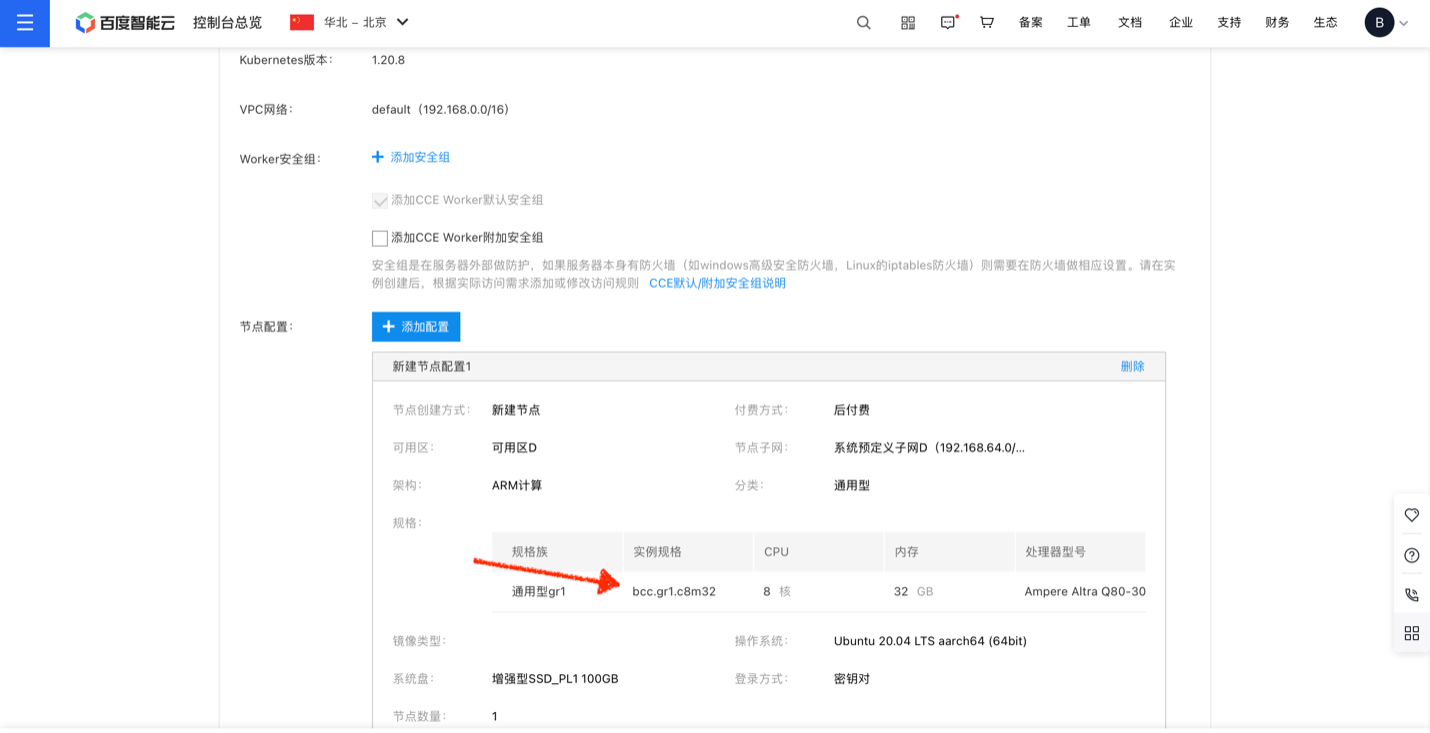
点击确认完成,CCE开始启动集群创建。整个过程需要数分钟时间。 待集群状态变成运行中后,即可下载集群凭证:
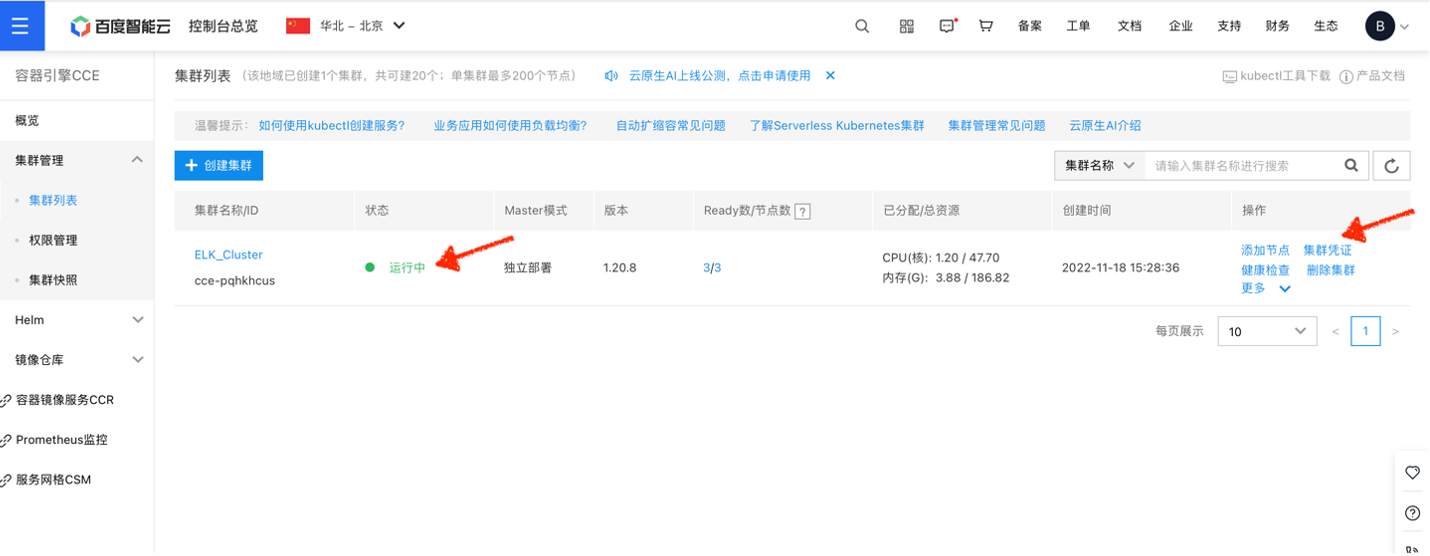
将下载后的凭证存放在kubectl 的默认配置路径:
$ mv kubectl.conf ~/.kube/config使用kubectl查询集群状态,当集群的Master和worker节点都显示Ready状态时,说明您的Arm 集群已经准备就绪,并且可以通过kubectl进行管理:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
192\. 168.64.10 Ready master 1d1h v1.20.8
192\. 168.64.11 Ready <none> 1d1h v1.20.8
192\. 168.64.12 Ready <none> 1d1h v1.20.8
192\. 168.64.13 Ready <none> 1d1h v1.20.8
192\. 168.64.8 Ready master 1d1h v1.20.8
192\. 168.64.9 Ready master 1d1h v1.20.8开始部署ELK!
预拉取容器镜像
为了加速部署过程中容器镜像拉取的速度,我们先通过镜像的容器仓库将部署过程中使用到的容器镜像拉取到Worker节点上并重新打上tag:
$ docker pull ampdemo/eck-operator:2.4.0
$ docker tag ampdemo/eck-operator:2.4.0 docker.elastic.co/eck/eck-operator:2.4.0
$ docker pull ampdemo/elasticsearch:8.4.1
$ docker tag ampdemo/elasticsearch:8.4.1 docker.elastic.co/elasticsearch/elasticsearch:8.4.1
$ docker pull ampdemo/filebeat:8.4.1
$ docker tag ampdemo/filebeat:8.4.1 docker.elastic.co/beats/filebeat:8.4.1
$ docker pull ampdemo/kibana:8.4.1
$ docker tag ampdemo/kibana:8.4.1 docker.elastic.co/kibana/kibana:8.4.1Operator 的部署
从Elastic网站下载定制并安装资源定义和RBAC规则:
$ kubectl create -f https://download.elastic.co/downloads/eck/2.4.0/crds.yaml
$ kubectl apply -f https://download.elastic.co/downloads/eck/2.4.0/operator.yaml稍等片刻后可以看到elastic-operator Pod 已经拉起并进入运行状态:
$ kubectl get pods -n elastic-system
NAME READY STATUS RESTARTS AGE
elastic-operator-0 1/1 Running 0 2m创建持久卷
在本例中,ELK集群将会申请1GiB的持久卷空间用作数据存储。因此,我们制备了20G的持久卷供ELK集群及将来的扩容使用。
$ cat <<EOF | kubectl apply -f - apiVersion: v1 kind: PersistentVolume metadata: name: elasticsearch-data namespace: default spec: capacity: storage: 20Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete local: path: /mnt/es_pv nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - 192.168.64.11 - 192.168.64.12 - 192.168.64.13 EOF
检查持久卷已成功创建:
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
elasticsearch-data 20Gi RWO Delete Available 5s
Elasticsearch 节点的部署
当Operator和持久卷已经就绪,我们可以通过如下命令开始Elasticsearch的部署:
$ cat <<EOF | kubectl apply -f -
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 8.4.1
nodeSets:
- name: default
count: 1
config:
node.store.allow_mmap: false
EOFElasticsearch节点会在数分钟内进入green和Ready状态:
$ kubectl get elasticsearch
NAME HEALTH NODES VERSION PHASE AGE
quickstart green 1 8.4.1 Ready 1m
Filebeat 的部署
当提到ELK,被广泛熟知的是Elasticsearch, Logstash 和Kibana的集合。Beat 是ELK家族的新成员,它是一个轻量级的开源数据传送器。在本范例中,我们将使用filebeat来收集每个Kubernetes节点上的容器日志。执行如下命令将Filebeat以DaemonSet部署在每台节点,并将日志以数据流的形式送往Elasticsearch:
$ cat <<EOF | kubectl apply -f -
apiVersion: beat.k8s.elastic.co/v1beta1
kind: Beat
metadata:
name: quickstart
spec:
type: filebeat
version: 8.4.1
elasticsearchRef:
name: quickstart
config:
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
daemonSet:
podTemplate:
spec:
dnsPolicy: ClusterFirstWithHostNet
hostNetwork: true
securityContext:
runAsUser: 0
containers:
- name: filebeat
volumeMounts:
- name: varlogcontainers
mountPath: /var/log/containers
- name: varlogpods
mountPath: /var/log/pods
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
- name: homedockercontainers
mountPath: /home
volumes:
- name: varlogcontainers
hostPath:
path: /var/log/containers
- name: varlogpods
hostPath:
path: /var/log/pods
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: homedockercontainers
hostPath:
path: /home
EOF同样的, 稍作等待beat 将进入green 的健康状态:
$ kubectl get beat
NAME HEALTH AVAILABLE EXPECTED TYPE VERSION AGE
quickstart green 3 3 filebeat 8.4.1 2m
Kibana 的部署
在完成Elasticsearch的部署后,我们需要Kibana来搜索,观察和分析数据。使用如下命令部署与当前Elasticsearch集群关联的Kibana实例:
$ cat <<EOF | kubectl apply -f - apiVersion: kibana.k8s.elastic.co/v1 kind: Kibana metadata: name: quickstart spec: version: 8.4.1 count: 1 elasticsearchRef: name: quickstart EOF
等待数分钟后,Kibana进入green健康状态:
$ kubectl get kibana
NAME HEALTH NODES VERSION AGE
quickstart green 1 8.4.1 2m分配一个公网IP以便从集群外访问Kibana:
$ kubectl expose deployment quickstart-kb \ --type=LoadBalancer \ --port 5601 \ --target-port 5601 service/quickstart-kb exposed
CCE将会准备一个LoadBalancer服务对象并将Kubernetes集群外部的访问重定向到后端Kibana的Pod:
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.255.0.1 <none> 443/TCP 1d3h
quickstart-es-default ClusterIP None <none> 9200/TCP 12h
quickstart-es-http ClusterIP 10.255.177.25 <none> 9200/TCP 12h
quickstart-es-internal-http ClusterIP 10.255.156.180 <none> 9200/TCP 12h
quickstart-es-transport ClusterIP None <none> 9300/TCP 12h
quickstart-kb LoadBalancer 10.255.223.4 120.48.90.143,192.168.0.3 5601:32716/TCP 12h
quickstart-kb-http ClusterIP 10.255.55.93 <none> 5601/TCP 12h
在本示例中,公网IP 120.48.90.143被分配给了Kibana实例。
Kibana 登录密码可通过如下命令获取:
$ kubectl get secret quickstart-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode; echo搭配用户名 elastic, 我们可以通过https://<EXTERNAL_IP>:5601 来尝试访问Kibana, 登录后在主页点击 “Explore on my own”.
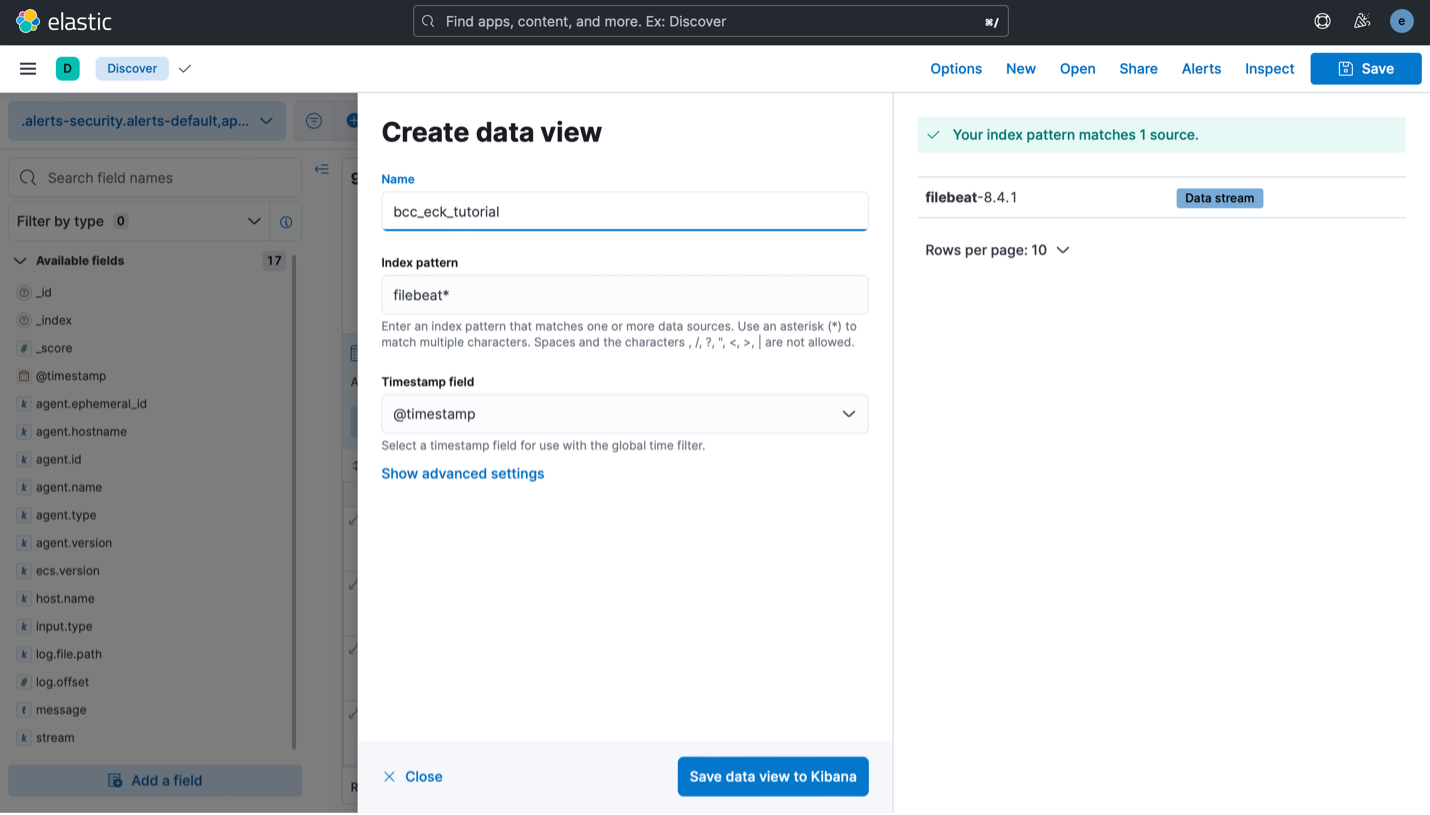
在Discover中选择“Create data view”,并在弹出窗口中给数据视图命名,如“bcc-eck-tutorial”,并在“filebeat-8.4.1”数据流中导入索引模式。
最终,我们可以在Kibana中查看Kubernetes 集群每个节点上Pod的日志。
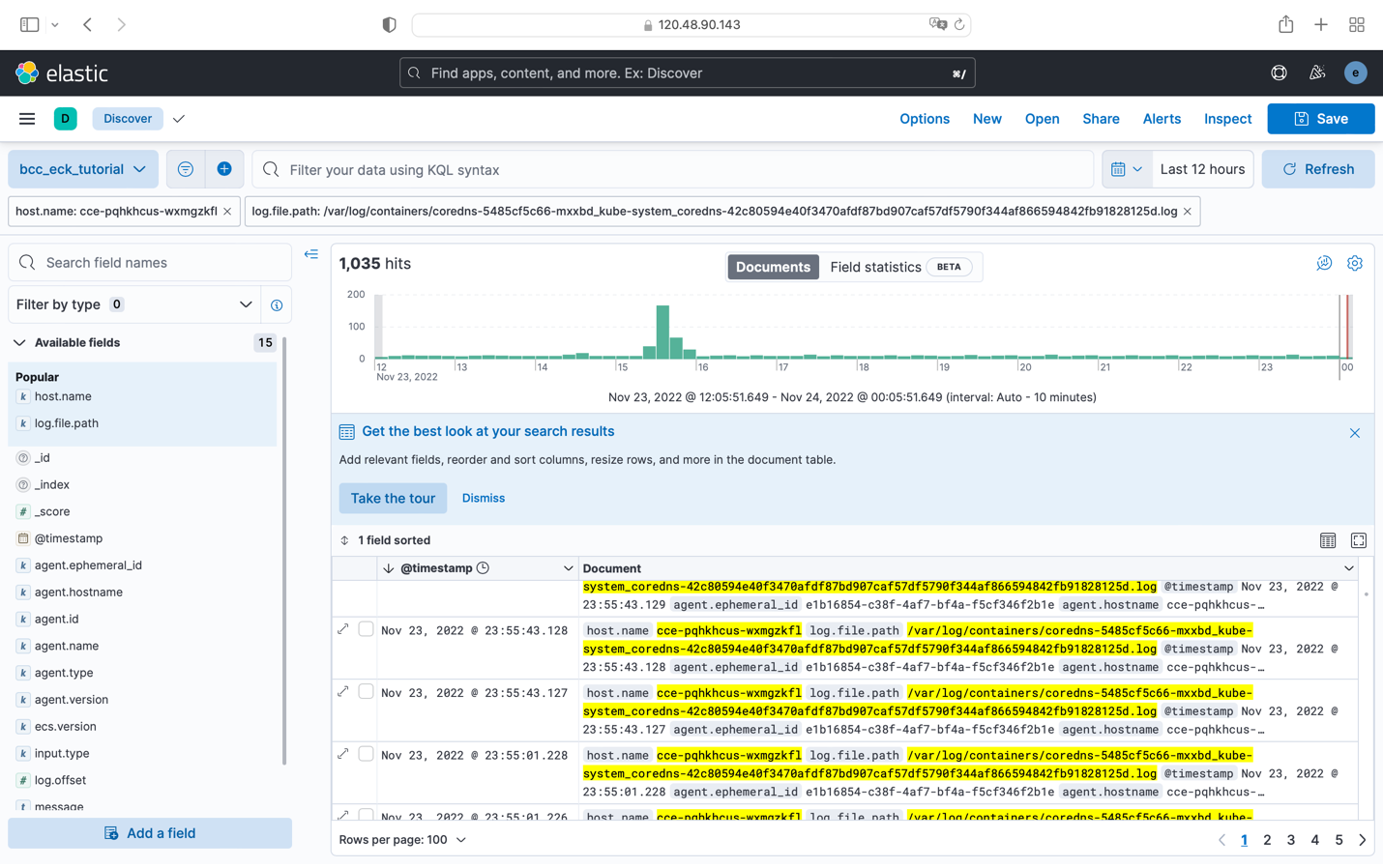
正如本示例所展示的,来自于CNCF Cloud Native的主流云原生项目如Elastic等,已提供对Arm64架构的支持。用户可以在基于Ampere Altra处理器的Arm64实例上感受到顺畅的部署体验。敬请访问Ampere Blog 进一步了解Ampere Altra处理家族的强大之处。
References:
1. https://www.elastic.co/what-is/elk-stack 2. https://www.elastic.co/guide/en/cloud-on-k8s/current/index.html
Ampere Computing
4655 Great America Parkway
Suite 601 Santa Clara, CA 95054

