
Adopting Ampere at Scale – How Uber Transitioned to Arm-based compute in an x86 Fleet

In February 2023, Uber announced its intent to work with Google Cloud and Oracle Cloud Infrastructure to migrate its applications to the cloud from on-premise data centers.
This blog reveals the details of that journey, focusing on the multi-architecture cloud aspect of the migration, with Arm-based OCI Ampere A1 and A2 compute coexisting with x86 compute. We’ll share insights on the process and benefits of moving to Oracle Cloud Infrastructure (OCI) Ampere-based Compute, why others should consider it, the challenges we faced, and how we overcame them.
The Motivation
To understand Uber's motivations for moving to Arm64-based compute, we must start by understanding OCI’s motivation for implementing Ampere processors in their data centers. One of the most obvious answers for all hyperscale Cloud Service Providers (CSPs) using Arm processors is energy costs. Arm is known for its low power designs for mobile devices and recently, data center products, but Ampere’s innovations push the boundaries of performance/Watt - running more efficiently than x86. This translates to substantial cost savings for OCI. Something that is less obvious is the space densification aspect, where more compute can be packed into a much smaller area in a data center, leading to better performance at a rack level, while saving on expensive real estate and infrastructure.
What about Uber’s motivations? They are motivated to achieve hardware and capacity diversity, providing the flexibility to choose the optimal infrastructure for Uber applications efficiently. There's also the environmental impact. Uber strives to be a zero-emissions platform company and high-performing, lower power compute helps us make huge strides in efficiency improvements. Data center space and energy savings for OCI translates to better price-performance and cost optimizations for Uber.
The Planning
Strategically, Uber plans to eventually move all infrastructure to the cloud. This decision marks a huge difference from the ‘all on-premise’ compute philosophy prior to 2023. This meant the infrastructure teams had to collaborate closely with the product teams to understand their compute requirements and design hardware that fit the needs of each product. This involved benchmarking, prototyping, and working with Oracle and Ampere to build out the platform. Luckily, the cloud gave us the flexibility to rapidly evaluate Ampere compute across different workload types.
Transitioning in Phases
Uber split the migration into four phases - SKU qualification, infrastructure readiness, technology readiness, and production rollout, as shown in Figure 1. We also decided to evaluate four different classes of workloads - stateless, stateful, batch, and AI/ML.
While the overall migration process was serial, we could operationalize some work across all workloads at relatively the same time depending on the phase.
Four Parallel Tracks:
- Stateless Services
- Operational Storage, Search & Real-Time Data
- Batch/Data Stack (Spark Batch & Presto)
- ML/AI (Training)
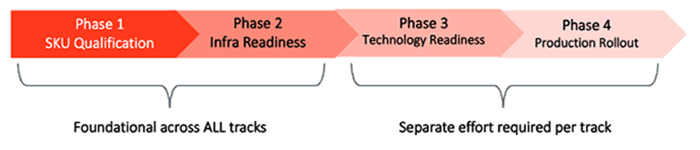
SKU Qualification
In this phase, we performed a fully automated, holistic SKU evaluation by running benchmarks representing our business. We did this to ensure that the hardware that we deploy can capably run production workloads. We also used it for early signals on host reliability, price-performance comparisons between different SKUs, and traffic routing based on hardware performance.
Infrastructure Readiness
Uber’s infrastructure has historically been on x86. Therefore, the simplest way to introduce Arm64 was to integrate at an IaaS level and deploy our own stack on top. This meant we needed layers of bootstrapping.
This involved creating a ‘golden image’, comprising the OS, kernel, and essential low-level host agents that can be provisioned and can communicate with our infra stack. That culminated in an Uber host.
Technology Readiness
Uber has ~5k microservices that are built out of a number of different language-specific monorepos. Given the majority of these were Go services and we had done the initial work to ensure the Go vertical monorepo supported arm64, it was the obvious choice for us to begin. Common issues we ran into were unmaintained Debian packages, older images, and Python 2 dependencies. Arm64 only supports versions beyond Debian 12, which implies no support for Python 2. We had to make sure our Python 2 dependencies were upgraded. We also had to review unmaintained Debian packages and ensure we could compile them.
Overcoming Performance Concerns
Uber has traditionally designed hardware four years out in the future. That means designing hardware that is a generational gap in terms of performance, ‘bigger and better’ than what we currently run in production.
Uber's infrastructure is basically set up in two major regions. Half of the traffic is routed to one region. Half of the traffic is routed to another region. New hardware would always be added to new zones, which means each zone could have generations of hardware. Combine this with the fact that we want all services distributed across all different availability zones for failure resiliency. So, when we look at our whole fleet collectively, there’s quite a large spectrum of our least performant SKU and E5, which is like the latest generation x86 on OCI now. When we map out all our production platforms, we see that OCI Ampere A1 actually falls in the upper right of our performance spectrum.
Production Rollout
When the production rollout started, we observed some unexpected behavior that was not apparent in our SKU qualification process. Performance of single-threaded processes was lower on Ampere A1 instances compared to the E4 x86 ones. An architecture discussion with Ampere clarified this discrepancy. Ampere processors use predictability and the scale out of modern cloud native workloads as design points. Forgoing technologies like opportunistic Turbo boost frequencies and Simultaneous Multithreading (SMT) are some examples of designing for the cloud. These technologies might end up improving performance by 20-30%, but they can introduce unpredictability in multi-tenant environments such as Uber’s production fleet. In dropping these features, Ampere has demonstrated improved scalability and throughput, especially in the presence of increased loads. The other valuable lesson for Uber was reinforcement of the potential disconnect between well-constructed micro benchmarks and real-world applications running in a live production environment. Benchmarks were conceived by smart performance engineers who, while ensuring representativeness, design them to be repeatable and predictable. The real world can be random, unpredictable, and messy.
Where is Uber now?
Uber has successfully converted a large part of our compute in OCI to Ampere A1 and A2 shapes and are currently qualifying the most critical workloads. Along the way, we have dealt with years of assumptions and tuning code has made for older architectures. Undoing these to support multi-architecture deployments is well worth the effort and can result in better performance and lower costs with a reduced carbon footprint.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



