
Adopting Ampere® at Scale – Evaluating Redis and Cassandra on OCI Ampere Compute

In our first blog from Uber and Ampere, we discussed our collaborative exploration and optimization of Oracle Cloud Infrastructure (OCI) Ampere powered instances versus traditional x86 compute historically deployed at Uber. We covered the motivations for the architectural transition, outlined a high-level process for planning the transition, and discussed some of the salient features of the Arm64 architecture. This blog will use two storage technologies, Redis and Cassandra, used heavily at Uber, as case studies to discuss performance evaluation, result optimization and learnings on the OCI Ampere instances.
An Overview of Infrastructure at Uber
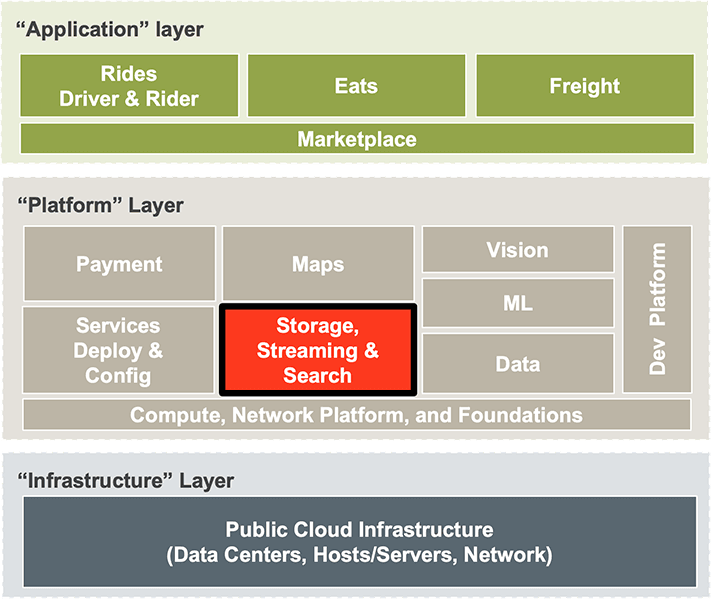
Let us start with a quick overview of the Uber Infrastructure stack.
At the bottom of this stack is the Infrastructure Layer, which is the layer closest to hardware, and the piece that abstracts away the underlying hardware components that are in the cloud or on premise.
Then comes the Platform Layer, which provides the core software libraries and infrastructure needed by higher-level applications. The Storage, Streaming, and Search “platform” is the one we will focus on in this blog which includes Redis, Cassandra, and several other storage technologies.
At the highest level are the various application service layers that support the Uber apps that readers should be familiar with, such as Uber Rides, Uber Eats, and Uber Freight. These applications use a combination of services across all three layers to fulfill an Uber trip or an Uber Eats order.
Specifically, Redis and Cassandra are designed to serve tens of millions of queries per second generated by the application users. In terms of compute footprint, it spans petabytes of data and memory, and cluster sizes vary from a handful of nodes to hundreds of nodes, depending on the application.
Redis Evaluation and Learnings
At Uber, Redis is referred to as TRedis - the ‘T’ stands for Twemproxy, a fast and lightweight proxy that supports both the redis and memcached protocols. It reduces the number of connections (and the cost of starting up and tearing down connections) to the backend Redis servers, which can get quite expensive at scale. Uber will eventually move to a Redis cluster, but the initial goal was to evaluate the existing TRedis workload and compare it to the existing fleet running on OCI E4 AMD instances.
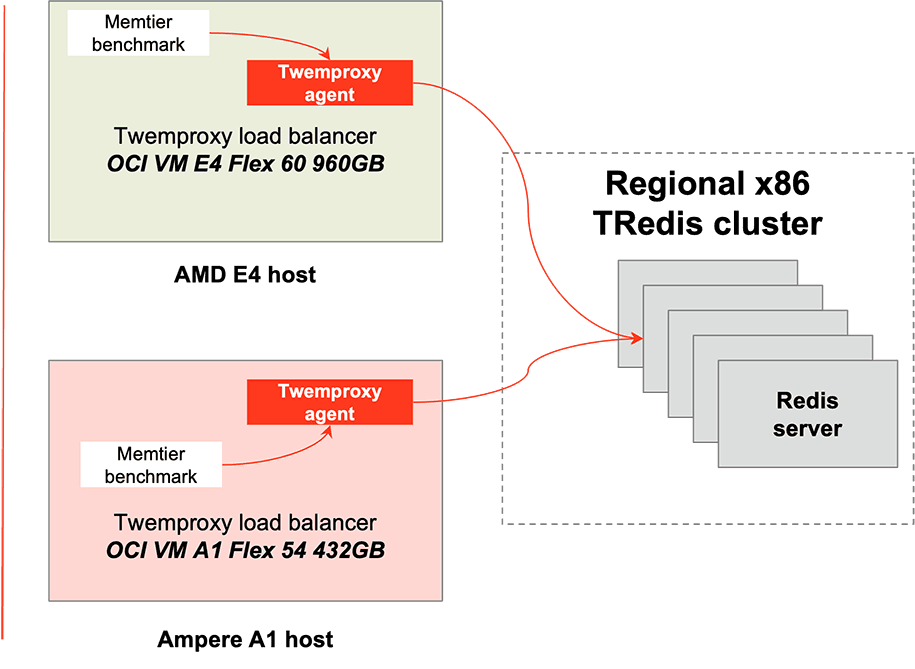
Our benchmarking configuration was designed to be simple, representative, and repeatable; something that the three parties - Ampere, Uber, and Oracle - could run independently and align on.
We used memtier_benchmark, a popular load generation utility, to create load to stress TRedis. The Twemproxy agents ran aside the memtier_benchmark instances on different VMs, ensuring requests were made across the network, an important piece of any Redis workflow. Anyone who has used Redis can testify to the importance of network latency and bandwidth tuning for optimal performance. We used up to five Redis nodes running on their own OCI E4 VMs.
The Problem and Debug Journey
Initial benchmarking showed OCI Ampere A1 instances had 57% lower throughput than the existing OCI E4 instances, which was certainly not expected. Experience with stateless applications had proven that the A1 instances would likely prevail on overall price-performance, however, a drastic drop in performance was unacceptable to the internal application teams at Uber.
This resulted in the creation of a three-way taskforce, between the Uber, Ampere, and Oracle engineering teams. This is where the simplicity of the test made alignment relatively straightforward - Ampere and Oracle were able to quickly replicate our findings, thus confirming the problem statement.
x86 and Arm64 - Are They Really that Different?
The first theory for the performance shortfall we had was based on the architecture differences between x86 and Arm64. Unlike the AMD E4 instances, Ampere A1 does not support Simultaneous Multithreading (SMT). SMT is a technology that allows more than one thread to run on each CPU core, thus improving utilization of underlying execution resources, but can have adverse effects on performance under certain scenarios. Refer to this blog for more detail on SMT and the pros and cons of this technology. For most x86 instances in the cloud, the number of vCPUs equals the number of logical cores, half of which are physical cores; the other half is made up of ‘siblings’, which share the underlying execution resources. This means, for workloads that use less than 50% of the processor resources, SMT is largely unused, and the underlying resources are uncontended. This gives x86 processors an advantage for lightly loaded scenarios, an advantage that diminishes with increasing loads in the real world. Our TRedis test was a lightly loaded scenario and E4 had an advantage due to this feature. The performance impact from running tests on both sibling SMT threads was found to be 35%.
A1 does not support opportunistic frequency increases either. This feature runs the CPUs at higher frequencies at the lower end of the utilization curve; AMD calls this Max Boost. For tests like our TRedis test that were running on a small number of CPU cores, Max Boost could certainly give E4 an advantage. Again, one that will lose value with increasing loads.
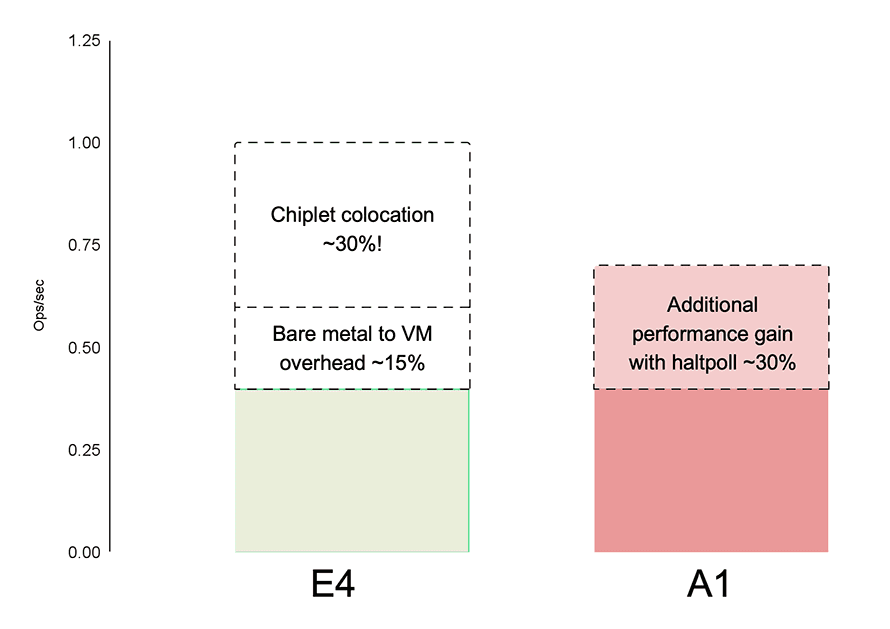
While digging deeper into the comparison between the two platforms, another architecture difference came into the forefront - the AMD E4 processor is composed of multiple chiplets, a decision that comes with benefits like lower costs and higher flexibility. From a software developer’s perspective, however, running applications in the cloud means you lose some control over chiplet configuration because the unit of compute is a virtual machine and processor core bin packing is a difficult problem for CSPs like Oracle. In our TRedis testing, we saw a 30% difference in performance between tests that were ideally co-located on one chiplet and those that crossed chiplet boundaries, something that should show up in variability studies (running across different VMs, zones, data centers and at different times of the day).
The third anomaly that was observed was that the data point for the baseline E4 performance was captured on a bare metal server, whereas the A1 performance was captured on OCI VMs. The tax of running the workload in a VM was observed to be 15% on E4.
Software Optimizations: The Icing on the Cake
Performance improvements rarely come only from hardware tuning. Software has a large role to play here, especially given the large number of software layers developers work with these days - hypervisor, guest OS, kernel, container, runtime environments, and finally the applications themselves.
After we were satisfied with the competitive performance of the OCI Ampere A1 platforms, we wanted to seek out ways to improve performance. So, we started with flame graphs based on Performance Monitoring Unit (PMU) data.
Our performance profiles pointed to softirqs and CPU wakeup latencies as problem areas. Given the TRedis test was ‘bursty’ (i.e. not constant load), there were frequent execution yields leading to processor halts and latencies in the guest VM.
Oracle recently upstreamed the cpuidle-haltpoll driver and governor for Arm64. This patchset aims to reduce the idle switching latencies in KVM guests by polling in the guest OS and reducing the VM exit costs. After compiling a kernel with haltpoll support, our TRedis test improved by an additional 30%, which validated our hypothesis and the profile data. This patch was evaluated and is now widely deployed in the Arm64 kernel at Uber.
After normalizing for these learnings, the performance of A1 came in line with E4 performance and even exceeded it on some tests as can be seen in the figure below.
Let’s now look at Cassandra
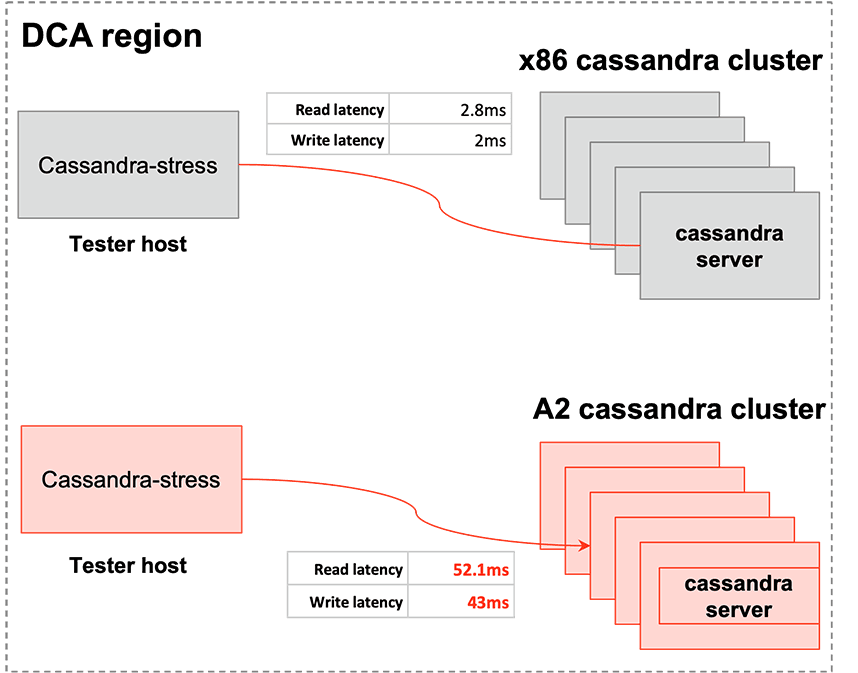
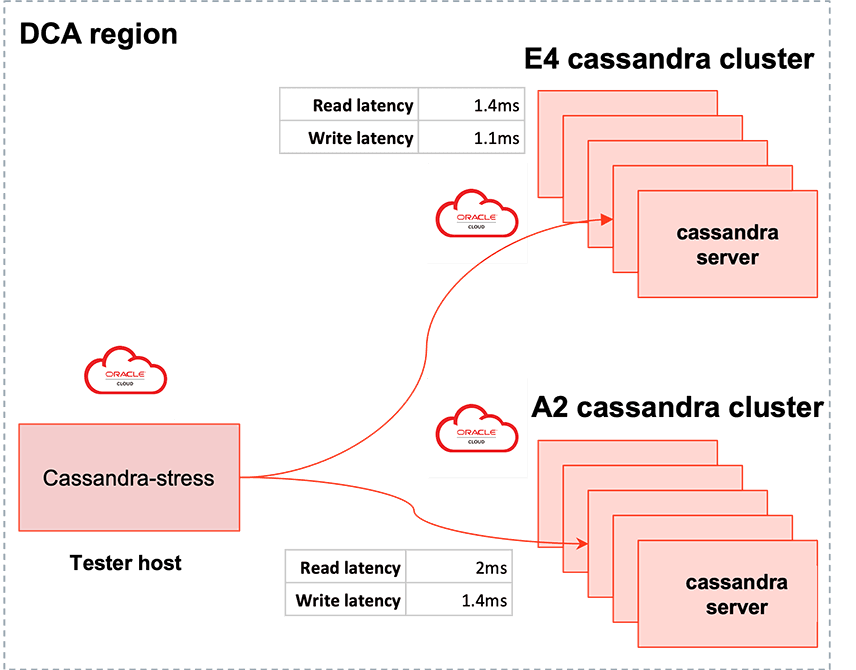
Similar to the Redis evaluation process, we initially saw Cassandra running on OCI Ampere at lower levels of performance. For the setup, we ran two nine node clusters - one with x86 hosts and the other with OCI Ampere A2 VMs. Uber was evaluating the OCI Ampere A2 Dense IO shape - a higher storage density solution against their equivalent x86 based high storage density solution. Designed for large databases, big data workloads, and applications that require high-performance local storage, DenseIO shapes include locally-attached NVMe-based SSDs. For the load generator hosts, we used cassandra-stress, a popular open-source benchmarking tool targeting the Cassandra nodes. The setup was configured to be representative of Uber’s traffic patterns. The overarching goal was to study the query latencies and throughput for the OCI Ampere A2 and AMD E4 Cassandra clusters under load.
Initial results showed higher-than-expected latencies for the OCI Ampere A2 DenseIO Cassandra cluster vs. a similar setup using on-prem AMD servers as shown in figure below, so the taskforce went into debug mode.
First up, we studied the query latencies while scaling the load and realized that the higher latencies were not due to the load levels; they were high even at very low load conditions. This suggested a bottleneck outside of the CPU compute blocks and pointed to I/O (networking and storage) as potential areas of investigation.
Network tests showed higher latencies for the A2 setup compared to the on premise E4 cluster. We root caused this to the differences in Maximum Transmission Unit (MTU) sizes between the two setups - Uber has historically used an MTU of 1500, whereas OCI uses 9000. The higher MTU size is efficient and beneficial when network packet sizes are larger. This test, however, used lower loads and smaller packet sizes, potentially resulting in higher TCP overheads and higher latencies. To validate this hypothesis, Uber ran a Cassandra cluster on OCI E4 nodes and observed higher latencies relative to the similar on-premise setup, thus confirming our theory. Continuing down the path of network optimizations, we studied the effects of Nagle’s algorithm; disabling it dropped network latencies down to expected levels and in line with Uber’s on premise setup, shown in the figure below.
What did Uber Learn from These Evaluations?
There is a misconception among developers today, that low power compute means low performance. When we start running real world applications, we find that is often not the case. Our benchmarking has demonstrated that the performance per core of Ampere processors is on par or better than its x86 equivalent competitors. A prerequisite to this statement - as developers, we need to put in the effort to understand the intricacies of the underlying architecture and how our applications interact with the underlying hardware. Understanding the lack of turbo frequencies helped us build confidence that performance would be more predictable once we deployed at scale in production. SMT is another feature that adds a layer of complexity that we hadn’t understood before we studied the Arm64 architecture. Taking these effects into account and normalizing them helped us better understand the hardware capabilities.
Benchmarking application clusters in a repeatable and representative manner requires extra care and attention - from host configurations and placement to optimizing network topologies for efficient internode communication.
Lastly, software optimization has a large role to play in achieving a balanced configuration, where compute, storage, and networking are all functioning optimally.
Our evaluation of critical parts of the Uber stack on the OCI Ampere A1 and A2 compute have created a mindset change for us. Some lessons learnt:
1. Baseline benchmarking should be treated as a starting point. While dealing with an architectural shift such as this one, understanding the microarchitecture and software optimizations can improve overall performance.
2. Rapid PoCs driven by a combination of theories and profile data to validate those theories can result in compelling results.
3. It is important to ensure benchmarks consider as many production scenarios as possible. For example, we would have had an incomplete view of performance had we focused only on single core performance and not studied performance as loads were scaled up.
This is just the beginning of our multi-cloud approach. Our journey to scale out on OCI Ampere-based compute continues. Here are some great resources for you to start your own transformation.
For more information:
- Ampere Computing - Oracle Partner Page
- Adopting Ampere at Scale – How Uber Transitioned to Arm-based compute in an x86 Fleet
- Oracle Ampere Compute - Get Started
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



