
Unleash the Power of Llama3 with Ampere-based OCI A1 Cloud Instances: A Testament to CPU-Based Large Language Model Inference
As computing and data processing becomes more distributed and complex, the focus of AI is shifting from initial training to more efficient AI inference. Meta’s Llama3, the most capable openly available Large Language Model (LLM) to date with the latest advancement in open-source LLMs, is now optimized for Ampere Cloud Native Processor on Oracle Cloud Infrastructure (OCI), offering an unprecedented performance and flexibility.
Trained on over 15T tokens of data, a training dataset 7X larger than that used for Llama2, Llama3 models take data and scale to new heights. Llama3’s openly accessible models excel at language nuances, contextual understanding, and complex tasks like translation and dialogue generation. Enterprises are now able to experience state-of-the-art Llama3 performance with Ampere-based OCI A1 shapes as a continuation of the ongoing Ampere llama.cpp optimization efforts.
Ampere Architecture
Ampere Cloud Native Processors optimize power draw, while offering industry-leading performance, scalability, and flexibility. This allows enterprises to efficiently handle varying workloads and accommodate increasingly demanding applications with growing data volumes and processing needs. They scale horizontally by leveraging cloud infrastructure, enabling the processing of large-scale datasets and supporting concurrent tasks. This is made possible through the single-threaded cores eliminating the noisy neighbor effect, higher core count improving the compute density, and lower power consumption per compute unit lowering the overall TCO.
Llama3 vs Llama2
With an increased focus on sustainability and power efficiency, the industry is trending towards smaller AI models to achieve efficiency, accuracy, cost, and ease of deployment. Llama3 8B may deliver similar or better performance than Llama2 70B on specific tasks due to its efficiency and lower risk of overfitting. Large 100B LLMs (e.g. PaLM2, 340B), or closed-source models, such as GPT4, can be computationally expensive and are often not ideal for deployments in resource-constrained environments. They also incur significant costs and can be cumbersome to deploy, especially on edge devices, due to their size and processing requirements. Llama3 8B, as a smaller model, will be easier to integrate into a variety of environments, enabling a wider adoption of generative AI capabilities.
Performance of Llama3 8B
Building upon the success of previous validations, Ampere AI’s engineering team fine-tuned llama.cpp for optimal performance on Ampere Cloud Native Processors. Ampere-based OCI A1 instances can now provide optimal support for Llama 3. This optimized Llama.cpp framework is available free of charge on DockerHub with the binaries accessible here.
Performance benchmarks conducted on Ampere-based OCI A1 Flex machines show the impressive capabilities of Llama 3 8B model, even at larger batch sizes. With throughput reaching up to 91 tokens per second on a single-node configuration, the inference speeds underscore the suitability of Ampere Cloud Native Processors for AI inference. Widespread availability across OCI regions ensures accessibility and scalability for users worldwide.
The table below details the key performance metrics on a single node OCI Ampere A1 Flex machine with 64 OCPU and 360 GB memory from concurrent batch size of 1 to 16 with 128 input and output token size. The performance of Llama 3 8B is on par to that of Llama 2 7B on Ampere A1.
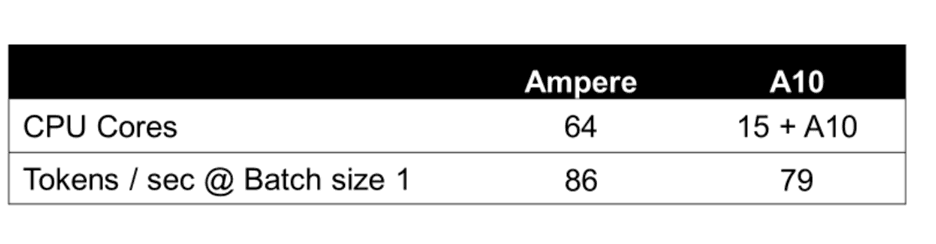
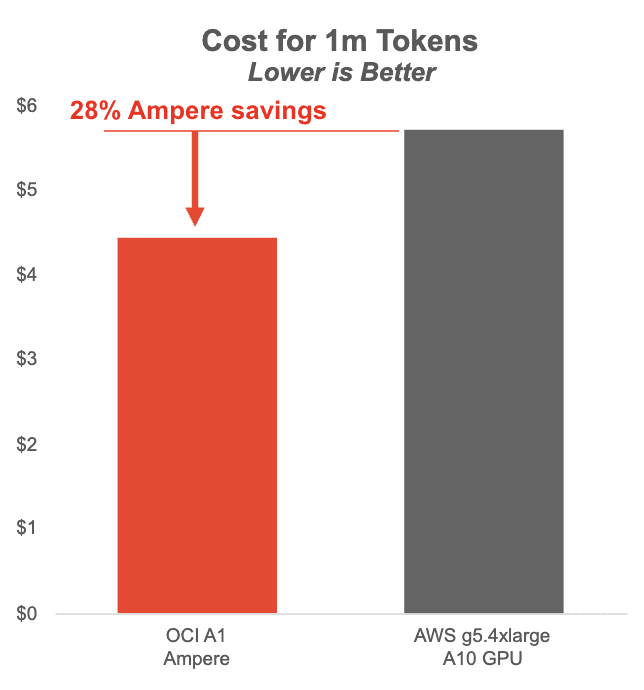
The chart below shows cost per million tokens with Llama3 8B running on Ampere-based OCI A1 instances vs NVIDIA A10 GPUs on AWS. Ampere A1 instances offer major cost savings at batch size 1-8, while providing a smoother user experience.
Ampere’s GPU-free AI Inference solution is class-leading for small batch and low latency applications.
Tokens per second (TPS): Number of tokens per second generated for the LLM inference request. This measurement includes time to first token and inter-token latency. Reported in number of tokens generated per second.
Server-side throughput (TP): This metric quantifies the total number of tokens generated by the server across all simultaneous user requests. It provides an aggregate measure of server capacity and efficiency to serve requests across users. This metric is reported in terms of TPS.
User-side inference speed (IS): This metric calculates the average token generation speed for individual user requests. It reflects the server's responsiveness to provide a service level of inference speed from the user's perspective. This metric is reported in terms of TPS.
See it in Action
Docker images can be vewed at DockerHub and llama.aio binaries at Llama.aio binaries free of cost. The images are available on most repositories like DockerHub, GitHub, and Ampere Computing’s AI solution webpage.
Ampere Model Library (AML) is an Ampere zoo model library developed and maintained by Ampere’s AI engineers. Users can access the AML public GitHub repository to validate the excellent performance of the Ampere Optimized AI Frameworks on our Ampere Altra® family of Cloud Native Processors.
To streamline the deployment process and test the performance, refer to the Ampere-powered easy-to-use LLM inference chatbot and custom marketplace images on OCI, offering user-friendly LLM inference llama.cpp and Serge UI open-source projects. This enables users to deploy and test Llama 3 on OCI and witness the seamless out-of-box deployment and instantaneous integration. Here’s a glimpse of the UI with OCI Ubuntu 22.04 marketplace image for Ampere A1 Compute on OCI:
Next Steps
As part of our ongoing commitment to innovation, Ampere and Oracle teams are actively working on expanding scenario support, including integration with Retrieval Augment Generation (RAG) and Lang chain functionalities. These enhancements will further elevate the capabilities of Llama 3 on Ampere Cloud Native Processors.
If you are an existing OCI customer, you can easily launch the Ampere A1 LLM Inference Getting Started Image. In addition, Oracle offers free credits of up to 3 months of 64 cores of Ampere A1 and 360GB memory to assist with validation of AI workloads on Ampere A1 flex shapes, with credits ending by December 31, 2024. Sign up today to take advantage of this limited time offer.
The availability of Ampere-optimized Llama 3 on Ampere-based OCI A1 instances represents a milestone advancement in CPU-based language model inference, with advantages of unparalleled price-performance, scalability, and ease of deployment. As we continue to push the boundaries of AI-driven computing, we invite you to join us on this journey of exploration and discovery. Stay tuned for more updates as we explore new possibilities to unlock the capabilities of generative AI with Ampere Cloud Native Processors.
Additional References Ampere A1 Compute | Oracle Price-Performance Llama2 Ampere A1 | Oracle
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



