
LLMs: Bigger is Not Always Better

Large Language Models (LLMs) are revolutionizing our interactions with technology. However, their size typically makes them resource-intensive, driving up costs and energy consumption. This post explores the relationship between LLM size, hardware requirements, and financial implications. We'll delve into real-world LLM trends and discuss strategies for building a more sustainable AI ecosystem by leveraging smaller, more efficient models.
Understanding Model Size: Parameters and Performance
Think of a LLM as having a brain with billions of "cells" called parameters. The more cells it has, the smarter and more capable it becomes. Traditionally, larger size models are associated with having both improved understanding and increased knowledge – like a brain having a boosted IQ and larger memory at the same time. Essentially, a larger LLM is like an expert with deep knowledge and understanding. But this expertise comes at a price. These larger models require more powerful computers and consume significantly more energy, increasing costs and environmental impact.
To better categorize language models, it's helpful to classify them by size. This chart illustrates different model classes with corresponding parameter counts and examples:
 Based on publicly available information (where available) and industry estimates (for closed-source models)
Based on publicly available information (where available) and industry estimates (for closed-source models)
LLMs are Getting Better and Smaller
Let’s look at Llama as an example. The rapid evolution of these models highlights a key trend in AI: prioritizing efficiency and performance.
When Llama 2 70B launched in August 2023, it was considered a top-tier foundational model. However, its massive size demanded powerful hardware like the NVIDIA H100 accelerator. Less than nine months later, Meta introduced Llama 3 8B, shrinking the model by almost 9x. This enabled it to run on smaller AI accelerators and even optimized CPUs, drastically reducing the required hardware costs and power usage. Impressively, Llama 3 8B surpassed its larger predecessor in accuracy benchmarks.
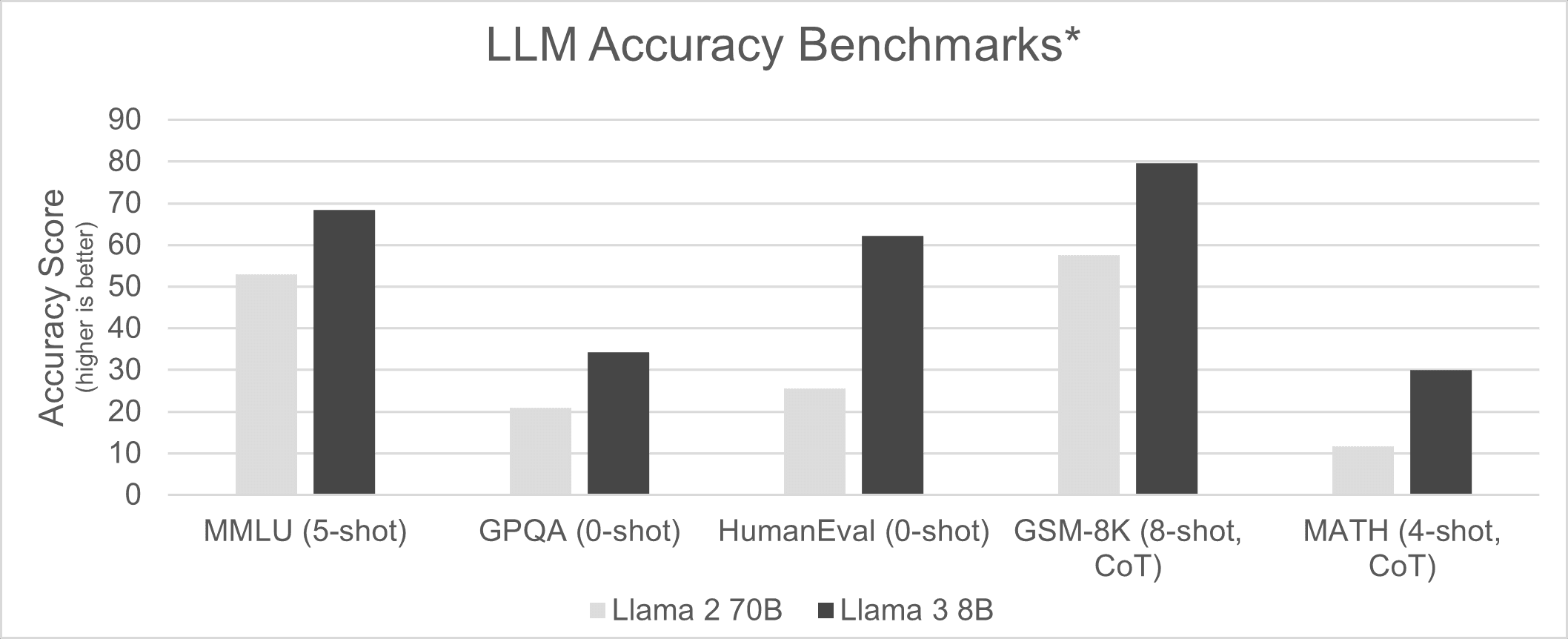 *Source and test methodology information: “Instruction tuned models” section from https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md#benchmarks
*Source and test methodology information: “Instruction tuned models” section from https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md#benchmarks
This trend continued with the release of Llama 3.2 in September 2024, featuring 1B and 3B variants suitable for several use cases. Even large class 3 models like Llama 3.2 405B are shrinking. In December 2024, Llama 3.3 70B arrived, achieving an 86.0 score on MMLU Chat, nearly matching the 88.6 score of the much larger predecessor Llama 3.2 405B.
This demonstrates that smaller class models can now rival the performance (accuracy) of previous gen larger class models while using less compute resources. This shift towards smaller, more efficient models is democratizing AI, helping make it more accessible and sustainable. Better yet, this trend toward SLMs is likely to continue in the future making it possible to expect new models being released that are multiple times smaller than current generation models.
Models Get More Use Case Specific
We're witnessing a growing trend towards creating specialized AI models through a process called knowledge distillation. This technique essentially "trims the fat" from LLMs, removing unnecessary information and often optimizing them for specific tasks.
Think of it like this: a large sales organization wanting to analyze its internal data doesn't need an AI model that can write poetry or design buildings. Similarly, an engineering department needing help with coding doesn't require a model with extensive knowledge of bird migration.
By distilling knowledge, we can create highly specialized models that excel in their designated areas. These models are leaner, faster, and more efficient because they're not burdened with extraneous information.
This trend towards domain-specific models offers several benefits:
- Improved accuracy: By focusing on a specific domain, these models can achieve higher accuracy and performance within their area of expertise.
- Reduced resource consumption: Smaller, more focused models generally require less computational power and memory, helping make them more cost-effective and energy-efficient.
- Enhanced deployability: Domain-specific models can be easily deployed on a wider range of hardware, including inferencing directly on AI-optimized CPUs.
As AI continues to evolve, we can expect to see a proliferation of these specialized models, each excelling in its own niche, from customer service and medical diagnosis to financial analysis, scientific research and beyond. We expect to see new potential being unlocked in various industries and applications around the world.
Is Your AI Going Too Fast?
While it's tempting to focus on maximizing the speed of AI inference (like boasting about a sports car's top speed), a more practical approach considers the actual needs of the user.
Just as a sports car is overkill for a daily commute, generating text at lightning speed can be excessive for human interaction. Some sources say, the average person reads at 200-300 English words per minute. AI models can easily surpass this, but an output of around 450 words per minute (10 tokens per second at around 1.3 tokens per English word) is generally sufficient based on collaboration with the AI Platform Alliance.
Prioritizing raw speed can lead to unnecessary costs and complexity. A more balanced approach focuses on delivering an optimal user experience without excessive resource consumption.
Cloud Native CPUs: A Flexible Solution For Inference
Cloud native CPUs, like AmpereOne®, offer a key advantage over GPUs: flexibility. Their ability to divvy up compute cores allows for multiple AI inference sessions to run concurrently. While GPUs generally handle single sessions at a time (with some exceptions like the NVIDIA H100's limited MIG capability), a CPU with 192 cores can be partitioned to accommodate numerous smaller tasks, including general purpose workloads.
This makes CPUs highly efficient for running smaller class 0 or class 1 AI models. While GPUs still excel with larger class 2 or class 3 models due to their raw computational power, CPUs provide a cost-effective and scalable solution for many common AI applications.
In essence, it's about choosing the right tool for the job. For large, complex models, AI hardware accelerators reign supreme. But for a higher volume of smaller tasks, the flexibility and efficiency of AI-optimized cloud native CPUs offer a compelling advantage.
Maximize Your LLM Efficiency Per Rack By Right-Sizing Your Compute
To make AI inference more accessible to everyone, we need to reduce its cost. This means choosing smaller AI models and running them on efficient hardware that maximizes the number of AI tasks we can perform simultaneously.
Most data center operators are constrained to anywhere between 10 and 20kW per rack in power budget. By optimizing model size and hardware choices, we can increase the density of AI inference per rack and make the technology more affordable and widely available.
Let’s demonstrate this by looking at a 12.5kW, 42U rack. Here's how many AI inference sessions you could run based on the model size and hardware while maintaining a minimum of 10 tokens per second (TPS):
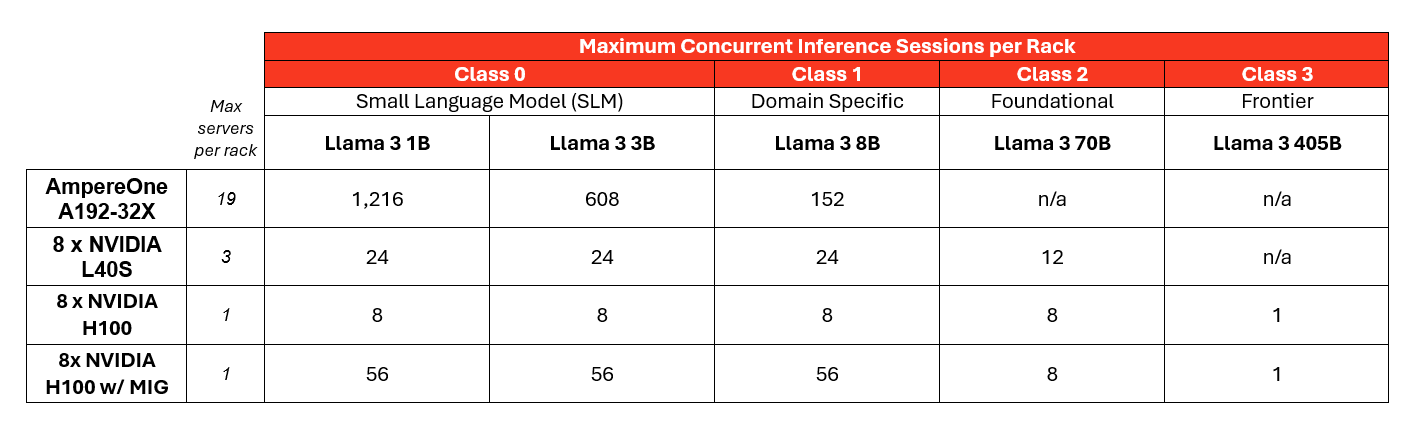
The key takeaway is this: smaller AI models (class 0 or 1) unlock a massive increase in the number of AI tasks you can run simultaneously in a rack, all while maintaining a satisfactory user experience. Here's why this is possible:
- Power Efficiency: AmpereOne servers are energy efficient, maximizing the number of servers that can run in an average rack.
- Partitioning: AmpereOne with 192 compute cores allows the creation of many concurrent inference sessions per rack.
- Ampere® AI Optimizer: Ampere AIO libraries help increase performance of LLMs such as Llama 3.
Building More Sustainable AI Compute
By optimizing AI models for specific use cases and industries, we can achieve significant reductions in their size and complexity. This targeted approach allows for the creation of smaller, more efficient models that require less computational power and can run on less expensive, more readily available cloud native hardware. This not only makes AI more accessible to individuals and smaller organizations but also promotes sustainability by reducing energy consumption.
This empowers individuals, researchers, and businesses of all sizes to leverage AI's potential, driving innovation and societal benefits across various domains. To learn more about Ampere’s innovation in the AI inference space visit the Ampere AI homepage. For information about our collaboration with industry leaders such as accelerator manufacturers, system builders or AI software providers, visit the AI Platform Alliance solution marketplace.
Disclaimer
All data and information contained herein is for informational purposes only and Ampere reserves the right to change it without notice. This document may contain technical inaccuracies, omissions and typographical errors, and Ampere is under no obligation to update or correct this information. Ampere makes no representations or warranties of any kind, including express or implied guarantees of noninfringement, merchantability, or fitness for a particular purpose, and assumes no liability of any kind. All information is provided “AS IS.” This document is not an offer or a binding commitment by Ampere.
System configurations, components, software versions, and testing environments that differ from those used in Ampere’s tests may result in different measurements than those obtained by Ampere.
©2024 Ampere Computing LLC. All Rights Reserved. Ampere, Ampere Computing, AmpereOne and the Ampere logo are all registered trademarks or trademarks of Ampere Computing LLC or its affiliates. All other product names used in this publication are for identification purposes only and may be trademarks of their respective companies.
Footnotes
For more information and assumptions, visit our Ampere data center efficiency white paper. Product and company names are for informational purposes only and may be trademarks of their respective owners.
Sessions per Rack: Rack is based on 42U rack with 12.5kW power budget. 2U and 1.0kW allocated as buffer for networking, management and PDU. Total concurrent sessions per rack calculated by multiplying the sessions per server with the maximum number of servers that fit in a rack (until space or power constraints are reached). Model precision running at 8 bit.
AmpereOne A192-32X server power assumed at 577W under load (SPEC CPU®2017 Integer Rate Result) in accordance with Ampere data center efficiency white paper. Sessions per server for AmpereOne A192-32X based on Ampere Computing LLC internal lab testing. For Llama 3 1B (Llama-3.2-1B-Instruct-Q8R16.gguf), 1 x AmpereOne A192-32X can support 64 concurrent users with TPS >10. For Llama 3 3B (Llama-3.2-3B-Instruct-Q8R16.gguf), 1 x AmpereOne A192-32X can support 32 concurrent users with TPS >10. For Llama 3 8B (Llama-3.1-8B-Q8R16.gguf), 1 x AmpereOne A192-32X can support 8 concurrent users with TPS >10. For Llama 3 70B and Llama 3 405B, 1 x AmpereOne A192-32X cannot support a service level of >10 TPS and hence is considered n/a.
Single server with 8 x NVIDIA L40S assumed to draw 3,097W under load. System power rollup assumed as follows: 2 x 270W for Intel Xeon Scalable 8380 CPU, 8 x 300W for NVIDIA L40S GPU, 1 x 157W for miscellaneous server power overhead. System assumed to use NVLINK to interconnect the GPUs. Single GPU assumed to handle a single inference session at a time. For Llama 3 405B, 8 x L40S with 48GB of memory cannot load 405B parameter model in 8 bit and hence is considered n/a. Per documentation as of December 12, 2024: https://resources.nvidia.com/en-us-l40s/l40s-datasheet-28413
Single server with 8 x NVIDIA H100 assumed to draw 6,297W under load. System power rollup assumed as follows: 2 x 270W for Intel Xeon Scalable 8380 CPU, 8 x 700W for NVIDIA H100 SXM-5 80GB GPU, 1 x 157W for miscellaneous server power overhead. System assumed to use NVLINK to interconnect the GPUs. Single GPU assumed to handle a single inference session at a time. NVIDIA Multi-Instance-GPU (MIG) feature assumed to deliver 7 sessions per H100 GPU. For Llama 3 70B and Llama 3 405B, using MIG to support 7 concurrent sessions limits the available memory per session to 80GB / 7 ≈ 11.4GB and thus is too memory constrained to load a 70B or 405B parameter model. Hence MIG would be configured for a single session only. Per manufacturer documentation as of December 12, 2024: https://www.nvidia.com/en-us/technologies/multi-instance-gpu/ and https://docs.nvidia.com/datacenter/tesla/mig-user-guide/.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



