
Revamp and Reclaim: Making Room for AI Compute

AI has become an integral part of daily life, whether through visible applications like mobile apps and digital commerce or behind-the-scenes processes like airline pricing algorithms or fraud detection systems activated with every credit card swipe. Generative AI, in particular, is expected to grow at double-digit rates over the next decade, potentially reaching over $1 trillion by 2032.
The democratization of AI has driven the demand for more powerful processors, particularly GPUs, which are an essential ingredient to build AI infrastructure. NVIDIA dominates that market, although AMD is also gaining traction. However, the power consumption of GPUs continues to rise, with some models now exceeding 1 kilowatt. This trend has contributed to a significant increase in global data center power consumption, expected to double between 2022 and 2026, creating a major capacity challenge for utility providers and businesses alike.
Currently, about 80% of data center operators face power constraints, with many limited to 10–20 kW per rack. While increasing processor performance and efficiency has traditionally justified higher total power consumption, many data center operators now are hitting their power ceilings, hampering innovation and growth. Expanding rack space or accommodating exotic cooling methods is often cost-prohibitive or restricted by space and regulations. Additionally, aging server infrastructure, with many servers over five years old, increases maintenance costs and security risks.
The most practical solution to this is to upgrade existing infrastructure. Timely server refreshes can drastically consolidate rack space, reduce operating costs, reclaim power budgets, and enable the deployment of modern servers capable of handling AI workloads. When evaluating which options exist for a refresh, operators need to start thinking differently than how the industry has trained them for decades. We’ve tolerated increasing power per processor as long as the performance per watt (i.e. the efficiency) of new generations increased. It meant that new servers ‘got better mileage’ than old servers, though maximum rack power budgets are finite and the industry is starting to reach those limits. By focusing on performance per rack instead, companies can optimize their existing power and space, allowing them to focus on business growth and innovation rather than data center limitations.
Cloud Native Processors from Ampere® are designed to deliver scale-out performance and leading efficiency. The custom compute cores behind AmpereOne® make it the best processor choice for refreshing aging server fleets. In our AmpereOne efficiency whitepaper, we elaborate on how AmpereOne’s CPU-level efficiency advantage translates as much as 67% better performance per rack for popular cloud native and AI workloads over AMD EPYC 9004 series processors.
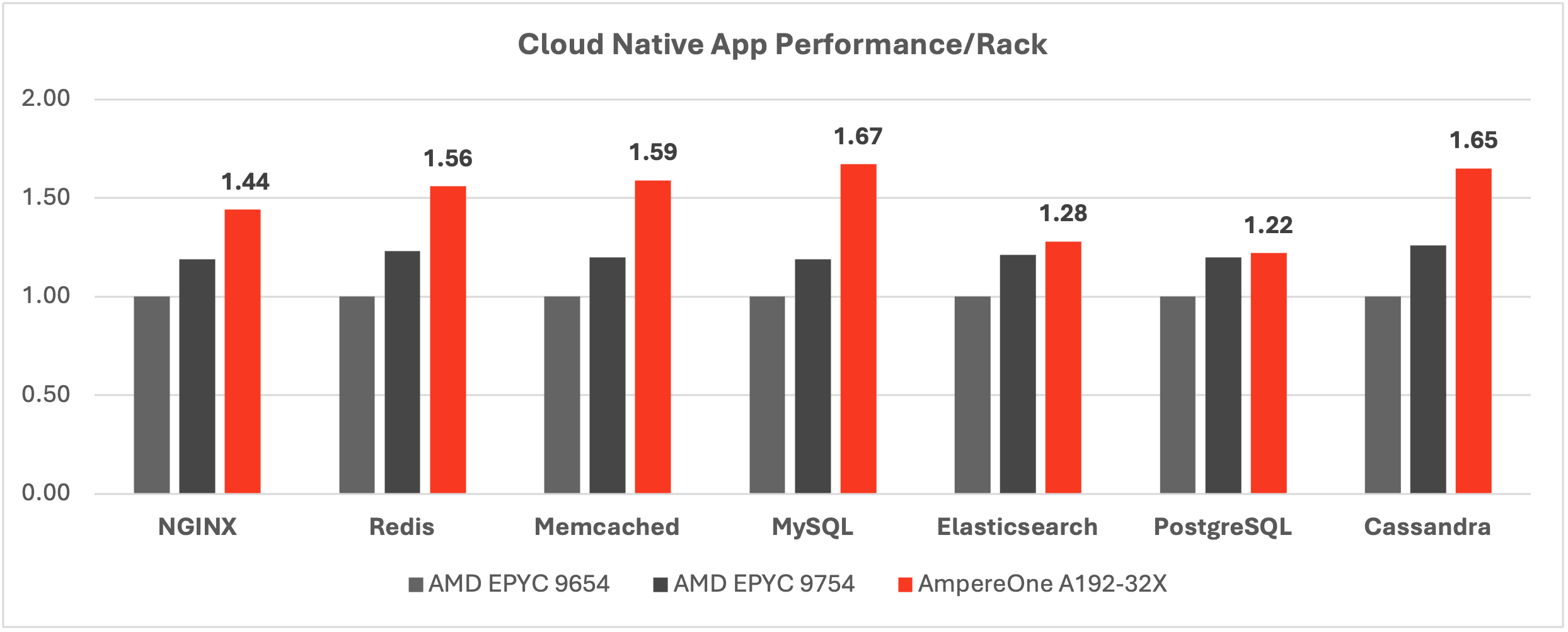
Below are seven open-source workloads, spanning from web servers and load balancers to databases to caching and in-memory data stores. They are popular for many modern web services because they handle web traffic management, data storage and performance optimization through caching.
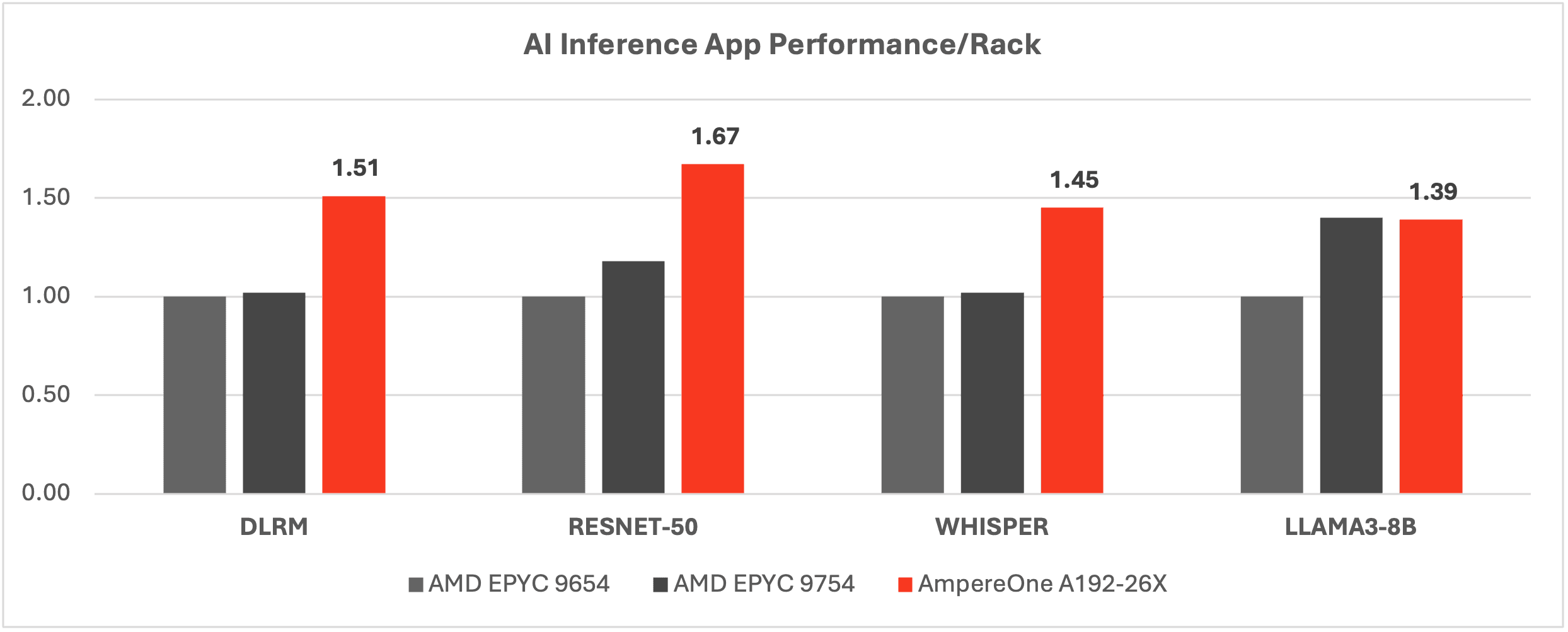
In the age of AI Compute, products and services across all kinds of sectors are enhanced by adding AI inference workloads to the general purpose workloads mentioned above. The next table showcases performance and efficiency of AmpereOne at the rack level for inference workloads such as recommender engines (DLRM), image processing (ResNet-50) as well as language-focused workloads (Whisper & Llama3). Such workloads are behind modern amenities like chatbots, seeing recommended products in e-commerce, being presented “shows you might like” on our favorite streaming platforms, or having real-time closed captions for live TV streams.
Aiming for maximum performance per rack is particularly meaningful for those enterprises and services providers mentioned earlier with limited power available per rack. As a result, even a modest-sized, AI-powered web service can benefit from AmpereOne. Compared to the output of 8 racks of AMD EPYC Genoa, AmpereOne can help to reduce rack space by 38%, reduce power budget by 37% and decrease acquisition costs by 49% without sacrificing performance levels. The below proxy web service consists of NGINX as the front-end web server, Redis as the key value store, Memcached as the in-memory database, MySQL as the relational database, and AI components DLRM and Llama3 as the recommender engine and chatbot, respectively.

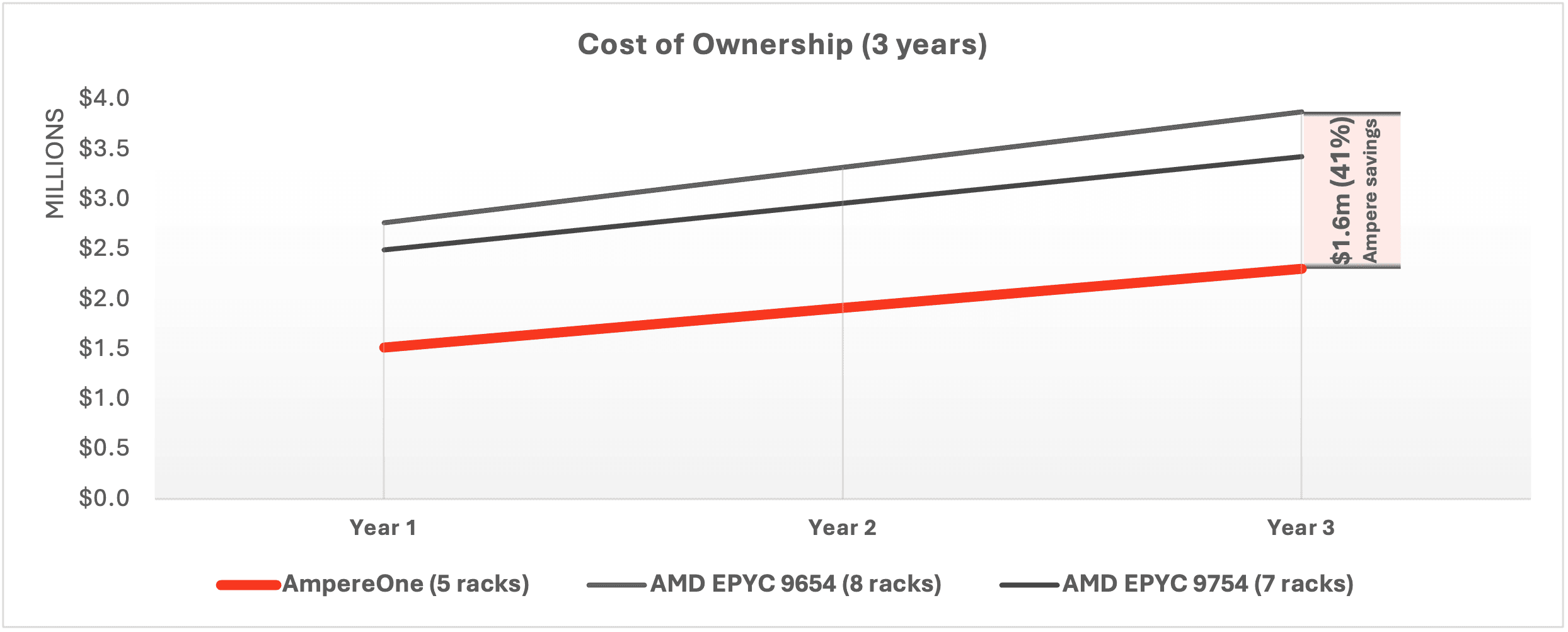
Repurposing budget, space, and power by refreshing aging servers is best achieved with AmpereOne. The culmination of the CapEx savings we just demonstrated, along with the OpEx savings achieved due to lower power consumption and lower administrative overhead, results in significant TCO savings on AmpereOne over a three-year time span. Operators can save 33% over AMD EPYC Bergamo in that time frame, or they could save as much as 41% if compared to AMD EPYC Genoa.
The AI tsunami continues to lower the entry barriers for companies of all sizes to implement AI at scale. Even small firms without the staff and resources to employ AI-focused teams can leverage a growing segment of service providers to start their AI journey and get to production swiftly. Hence, the importance of consolidating legacy infrastructure to make room for AI expansion is higher than ever before. Don’t miss out. Start your journey NOW.
Learn more about the scale-out performance and efficiency advantage of AmpereOne in our whitepaper.
Disclaimer:
All data and information contained herein is for informational purposes only and Ampere reserves the right to change it without notice. This document may contain technical inaccuracies, omissions and typographical errors, and Ampere is under no obligation to update or correct this information. Ampere makes no representations or warranties of any kind, including express or implied guarantees of noninfringement, merchantability, or fitness for a particular purpose, and assumes no liability of any kind. All information is provided “AS IS.” This document is not an offer or a binding commitment by Ampere.
System configurations, components, software versions, and testing environments that differ from those used in Ampere’s tests may result in different measurements than those obtained by Ampere.
©2024 Ampere Computing LLC. All Rights Reserved. Ampere, Ampere Computing, AmpereOne and the Ampere logo are all registered trademarks or trademarks of Ampere Computing LLC or its affiliates. All other product names used in this publication are for identification purposes only and may be trademarks of their respective companies.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



