
Data Analytics - Spark
Features
Spark is a Open source framework for faster data processing, can cache to memory for processing its tasks and has Spark SQL, its own query language
Spark's Stack
Apache Spark Core
Spark Core is the underlying general execution engine for the Spark platform that all other functionality is built upon. It provides in-memory computing and referencing datasets in external storage systems. Spark Core is also home to the API that defines resilient distributed datasets (RDDs), which are Spark’s main programming abstraction. Spark Core provides many APIs for building and manipulating these collections that include Java, Python, Scala, R and support SQL.
Spark SQL
Spark SQL is Apache Spark’s module for working with structured data.
Spark Streaming
This component allows Spark to process real-time streaming data. Data can be ingested from many sources like Kafka, and HDFS. Then the data is processed using spark algorithms and pushed out to file systems, and databases
MLlib (Machine Learning Library)
Apache Spark has MLlib that contains a wide array of machine learning algorithms. It also includes other tools for constructing, evaluating, and tuning ML Pipelines.
GraphX
Spark also comes with a library to manipulate graph databases and perform computations called GraphX. GraphX unifies ETL (Extract, Transform, and Load) processes, exploratory analysis, and iterative graph computation within a single system.
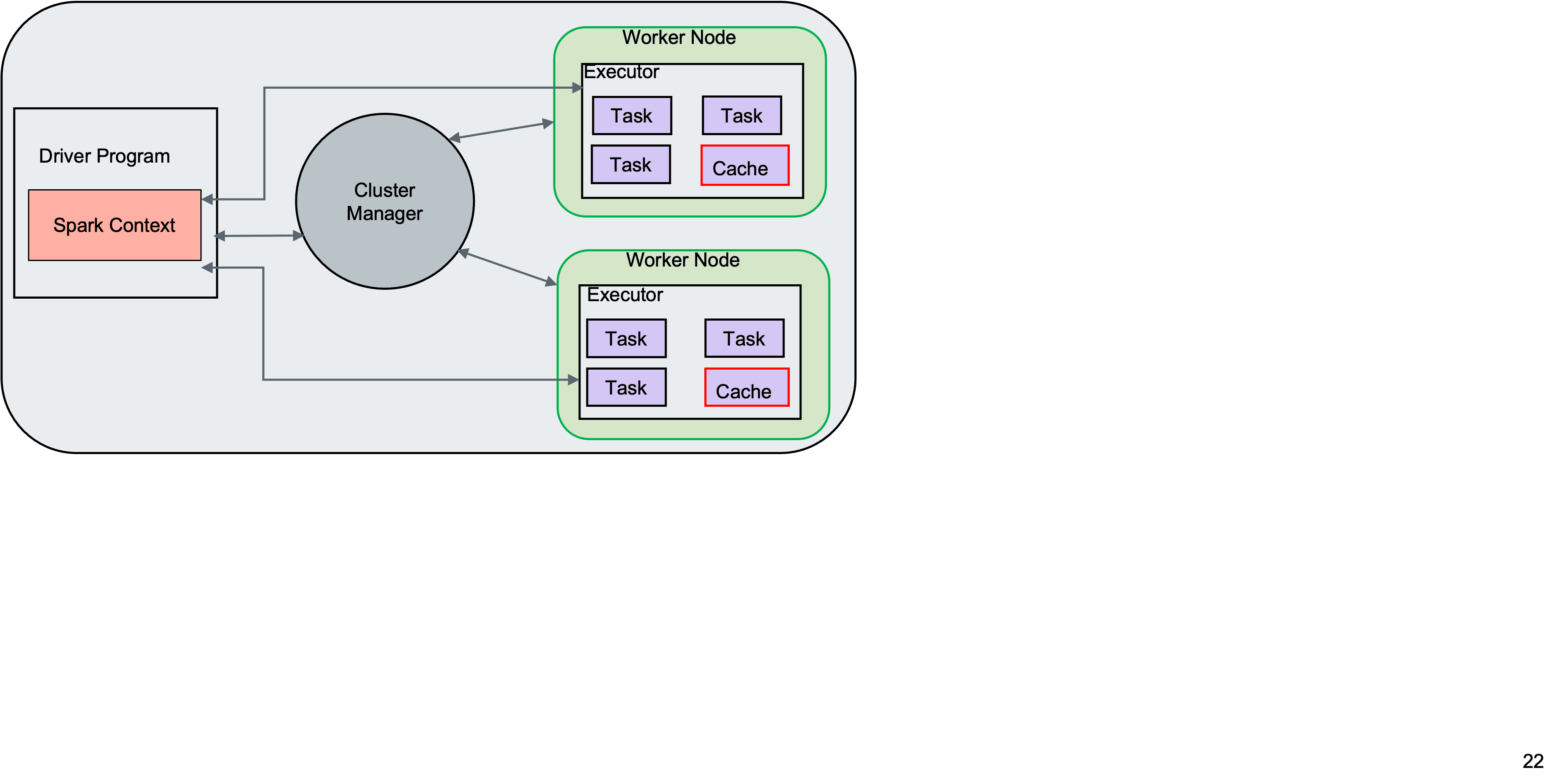
Key Components of Spark Architecutre
1. Spark Driver 2. Spark Executors 3. Cluster Manager
Spark Driver is the controller of the Spark execution engine and maintains the states of the Spark cluster. It interfaces with the cluster manager to get physical resources like vCPU and memory and launches the executors.
The actual tasks are processed by the Spark executors assigned by the driver. They run the tasks and report back their results and state.
The cluster manager is responsible for maintaining the cluster of machines that will run the Spark application.
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



