
How to Choose the Best Processor for Artificial Intelligence (AI)

What’s the best choice of processor to meet the compute challenges of AI?
Choosing the right CPU or GPU for long-running compute-intensive AI training and large-scale inferencing comes down to right-sizing the compute solution for your application. The latest Ampere Cloud Native Processors provide power efficient, high-performance alternative to expensive, power-hungry legacy x86 processors for AI inference applications and a cost-effective companion to GPUs for AI training and LLM inference.
The evolution of AI computing—from the first instances in the 1950s to the more sophisticated machine learning, deep learning, and even generative AI technologies emerging today—has been driven by the need for high performance compute, but it comes at a high cost for research and training models.
We have now begun the mass adoption phase of AI technology, which makes the existing practice of over-provisioning compute for AI inference cost prohibitive—both the unit cost of the hardware and the cost of power to run it. The practice of using GPU-only VMs for every type of AI workload is giving way to alternative solutions that reduce the massive power consumption of AI computing.
To highlight the sheer volume of energy required to run AI, a recent article from Bloomberg details just how much more energy AI consumes versus traditional computing: ChatGPT3 with 175 billion parameters took 1.287 gigawatt hours, or about as much electricity as 120 US homes would consume in a year. Newer models like ChatGPT4—with an estimated 1.7 trillion parameters—would require a lot more energy.
Given the rapid rise in AI power consumption, the need to right-size and reduce the amount of required compute is greater than ever. Cloud Native computing can help reduce processing costs—setting the stage for right-sizing at the hardware level to meet current and future computational needs and reducing energy consumption.
Right-Sizing Meets Compute and Efficiency Demands
An innovation in CPU architecture—Cloud Native Processors—is providing a viable alternative to the high cost and power consumption of legacy x86 processors for AI inference. Right sizing for your AI application means deciding when to use CPU-only and when to combine the power efficiency, scalability, and compute performance of Cloud Native Processors with the parallel computing capabilities of GPU.
For higher value and power efficient alternatives to expensive and power-hungry legacy AI solutions, follow these three simple guidelines:
1. Deploy only the amount of compute you need to meet the performance requirements of your application and use general purpose rather than specialized processors as broadly as possible to maintain flexibility for future compute needs.
2. Switch AI CPU-only inferencing from legacy x86 processors to Cloud Native Processors. With the performance gains of Ampere’s Cloud Native Processors, you may be able to deploy as CPU-only for a wider range of AI workloads than with legacy x86 processors.
3. Combine GPU with the power efficient Cloud Native Processors for heavier AI training or LLM inferencing workloads.
Read more about the energy efficiency of Cloud Native Processors in this guide to “Triple Data Center Efficiency with Cloud Native Processors“.
Deploy Only the Amount of Compute You Need
In the research and training phase of AI technology development, GPUs served as the go-to processor for all AI applications—both modeling and inference. While GPUs have driven development, they are compute overkill for many AI applications—particularly batch or bulk inference.
Batch inference applications are less demanding workloads and don’t require the processing power of a GPU: making the purchase of GPUs for this purpose akin to buying a fancy sports car to drive five miles to work—it’s simply more than you need. When the same expensive GPU hardware is used to run both large and small models, small model jobs may only use a small percent of the GPU’s capacity. In these instances, replacing the GPU with a CPU saves power, space, and cost.
Customers that follow default recommendations to use GPU solutions are missing at least two other better-sized options for their batch work. The first option is to switch out GPUs for high performing Cloud Native Processors for AI inferencing. Another option is to add a GPU to a Cloud Native Processor for more efficient LLM inference and training work. This is called “right-sized computing.”
Right-sized computing for artificial intelligence applications is illustrated in this model where performance and compute needs are measured against the power consumed. In this model, inference-only AI compute is served best by a CPU-only solution, while applications that include more performance can be run on a CPU and GPU combination.
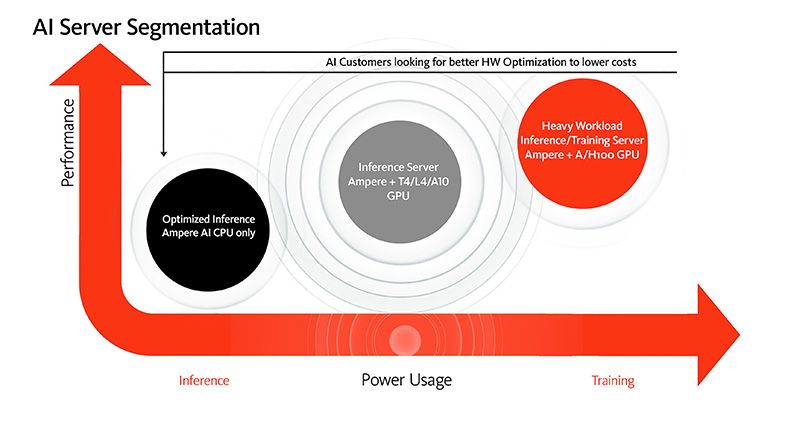
Of course, the CPU you choose will also determine the amount of power and performance per watt you achieve. The performance benefits of Cloud Native Processors and the Ampere optimized AI software make these CPUs ideal for running AI inference workloads.
Switch AI inferencing to Cloud Native Processors Only
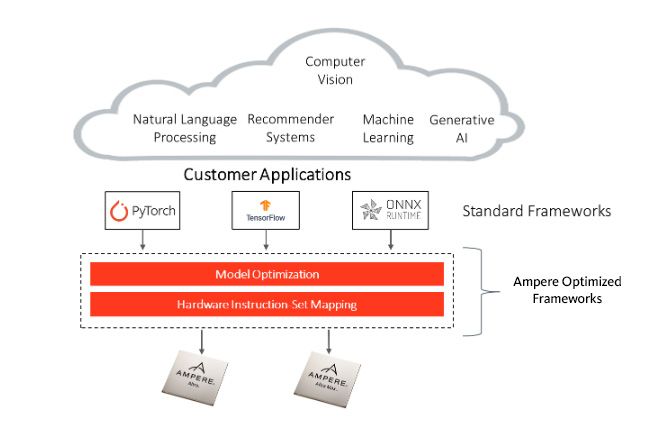
Join the many developers and designers in the cloud native community who are discovering they can implement AI inference effectively and efficiently with a CPU alone—if that CPU is a Cloud Native Processor. Ampere Optimized AI Frameworks supports all models developed in the most popular AI frameworks, including PyTorch, TensorFlow, and ONNX Runtime. The integration is seamless and requires no changes to the API or additional model coding.
The Ampere Altra family of Cloud Native Processors perform significantly better than legacy x86 processors for AI inference, including:
- Up to 4x better performance for computer vision workloads*
- Up to 3x better perf/Watt for common NLP workloads*
More efficient AI inference is made possible by Ampere AI optimized software. Ampere AI enabled software frameworks optimize the processing of AI and ML inference workloads on Ampere processors. Ampere AI enables CPU-based inference workloads to take advantage of the cost, performance, scalability, and power efficiency of Ampere processors, while enabling users to program with common and standard AI frameworks. This set of frameworks are easy to use, require no code conversion—and are free.
The amazing inference performance of Ampere Altra Family processors is best accomplished by using the unique support of the fp16 data format—providing up to 2x additional* acceleration over the fp32 data format with negligible accuracy loss.
Combine GPU with Power Efficient CPU for AI Training and Inference
In AI applications requiring a GPU, the heavy AI workload is processed on the GPU while a CPU is required to act as a system host. In this application, the performance of the CPU is always the same—regardless of which CPU you use because the GPU determines the performance of the system.
The difference between CPUs is in their overall efficiency. By using Cloud Native Processors, the power efficiency you gain over legacy x86 CPUs can significantly reduce overall system power usage*—while delivering the exact same performance.
By saving even a couple hundred watts per server with a Cloud Native Processor, you open up the potential to add one more server per rack. While it seems like a small gain, one server in every rack equates to an incremental increase in compute density across a data center. In addition, saving power at the server level may result in additional cost and power savings from reduced reliance on cooling systems.
In combination with a GPU, Cloud Native Processors help to achieve the target performance while reducing energy consumption and overall costs.
The Future of AI is Powerful, Efficient, and Open
As the world races toward bringing AI into the way we live, work, and play the most critical hurdle we need to overcome is lowering the cost for mass adoption. Right-sized compute and optimized models lead to efficiency at scale.
A key to right sizing is ensuring that hardware solutions not only meet your computational needs today, but also allow you to grow and future-proof your application. Ampere’s Families of Cloud Native Processors have a broad range of options to allow scale enough to meet today’s needs while providing the flexibility to serve future requirements easily. Whether you choose a CPU-only approach or a GPU plus CPU solution, cloud native architecture has all the performance and efficiency advantages needed to build for today and in anticipation of the future.
Built for cloud computing, Ampere Cloud Native Processors deliver predictable high performance, platform scalability, and power efficiency unprecedented in the industry.
Talk to our expert sales team about partnerships and to get more information or get trial access to Ampere Systems through our Developer Access Programs.
Footnotes:
*The AI computing comparisons here are based on benchmark comparisons measured and published by Ampere Computing. Details and footnotes are available here.
Disclaimer
All data and information contained in or disclosed by this document are for informational purposes only and are subject to change.
This document is not to be used, copied, or reproduced in its entirety, or presented to others without the express written permission of Ampere®.
© 2023 Ampere® Computing LLC. All rights reserved. Ampere®, Ampere® Computing, Altra and the Ampere® logo are all trademarks of Ampere® Computing LLC or its affiliates. Other company or product names used in this publication are for identification purposes only and may be trademarks of their respective companies.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



