
Why Big Data Workloads Deserve AmpereOne M

If your organization runs Apache Hadoop or Apache Spark, you already know these frameworks are the backbone of modern data analytics, and are essential for modern AI workflows. Hadoop distributes massive datasets across clusters for at-scale processing, while Spark accelerates that work by keeping data in memory rather than writing it back to disk at every step. Both are data-hungry by design, and that means the processor underneath has an outsized impact on performance.
New benchmark results and reference architectures show that AmpereOne® M delivers dramatic performance gains for both workloads, driven by architectural choices that align precisely with what big data frameworks need most: cores, memory bandwidth, and power efficiency.
What Hadoop and Spark Actually Do
If you haven't lived inside a data engineering team, a quick primer. Hadoop's signature move is TeraSort-style batch processing: it splits enormous datasets into blocks, distributes them across a cluster, and crunches through them in parallel using its MapReduce engine. Spark does similar work but with a different approach. It caches intermediate data in RAM so that iterative algorithms and multi-step analytics pipelines don't have to keep reading and writing from disk. Both frameworks scale horizontally by adding more nodes, and they run natively on Arm-based processors without modification.
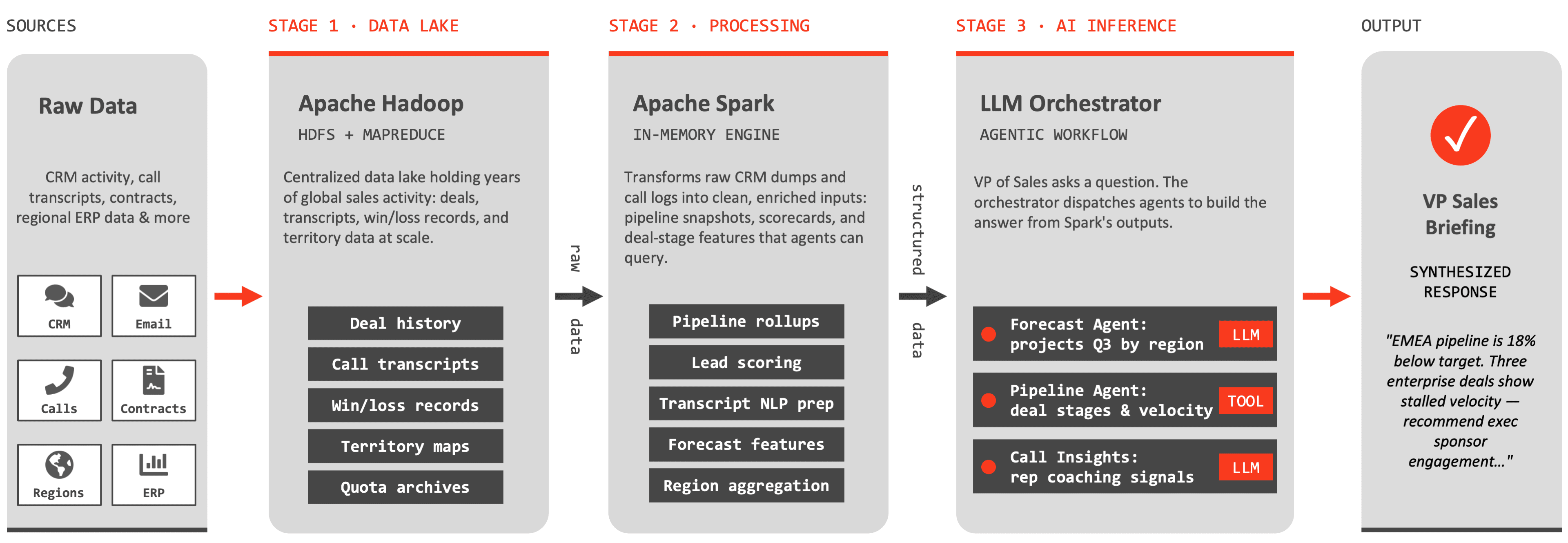
Imagine a global sales organization that pulls data from CRMs, call logs, contracts, regional ERPs and territory mapping tools to create executive pipeline briefings on demand. Here, Hadoop would serve as the centralized data lake, storing and serving years of deal history, call transcripts, win/loss records and quota archives across regions. Spark then takes that raw data and transforms it into something actionable: scoring leads, aggregating pipeline metrics by territory, preparing call transcripts for NLP analysis and more. Only after Spark does this pre-processing does the inference layer take over, which orchestrates different agents to project quarterly revenue by region, to query deal velocity, or to extract coaching opportunities from recent calls, for example. The below diagram illustrates this sequential from a raw source of data to a synthesized VP-level briefing.
AmpereOne® M Performance Boosts
Ampere® tested both Hadoop and Spark on identical three-node clusters, comparing the current-generation AmpereOne® M 192-core processor with its predecessor, the Ampere® Altra® 128-core processor. The results tell a clear story.
Up to 39% more performance and 35% more efficiency on AmpereOne M for Spark and Hadoop workloads
For Hadoop TeraSort, AmpereOne® M delivered a 39% throughput improvement over Altra on a single node, along with a 30% efficiency improvement (performance/watt). Spark TeraSort showed a 31% throughput gain and 35% better energy efficiency. Spark's TPC-DS benchmark, a demanding suite of 99 SQL queries simulating real-world decision-support workloads, was even more striking: queries completed in 50% less time on AmpereOne® M.
Both workloads also demonstrated near-linear scalability, meaning three nodes produced nearly three times the throughput of a single node. That predictability matters when planning capacity and budgets.
Why the AmpereOne® M Architecture Matters
These gains aren't just about a faster clock. Two architectural advances make the AmpereOne® M especially well-suited for data-intensive work.
First, the jump from 128 to 192 single-threaded cores means more parallel tasks can run simultaneously. Both Hadoop MapReduce and Spark executors are designed to decompose jobs into many small tasks. More cores means more tasks in flight at once.
Second, and arguably the biggest differentiator, AmpereOne® M provides 12 channels of DDR5 memory running at 5600 MT/s, compared to 8 channels of DDR4 on Ampere® Altra®. Big data workloads are fundamentally memory-bandwidth-bound. Hadoop is constantly reading and writing data blocks across its distributed file system, and Spark's entire value proposition depends on keeping data in RAM. A 50% increase in memory channels translates directly into more data flowing to and from the cores every cycle, which is exactly why the benchmark improvements are so significant.
Configuring Page Sizes for Extra Throughput
Both Ampere reference architectures tested a simple operating system change that are easy to overlook: switching the Linux kernel from the default 4KB memory page size to 64KB.
Think of it this way. Memory pages are like shipping containers for data moving between RAM and the processor. With 4KB pages, the system is essentially using thousands of tiny envelopes to deliver a large shipment — each one requires its own address lookup and handling overhead. Switching to 64KB pages is like upgrading to full-size shipping containers: you move 16 times more data per trip, with far fewer trips and far less administrative overhead for the system to track.
The results were substantial. Hadoop TeraSort throughput improved by approximately 30% with 64KB pages, while Spark TeraSort saw an even larger 40% boost. Even the SQL-heavy TPC-DS workload on Spark picked up a 9% improvement. Modern Linux distributions support large-page kernels natively on Arm64, making this a straightforward configuration change with no application code modifications required.
Up to 40% performance boost implementing 64KB page size kernels
Caveat: Running 64k page size doesn’t make sense in every deployment scenario. We caution to test before deploying into production, especially if those same nodes run other applications alongside the data stack. Though, when your workload processes large data in bulk – which is what Hadoop and Spark are excellent in doing – then, it’s merely a straightforward config change.
The Bottom Line
Organizations running big data workloads should take note: the combination of AmpereOne® M's 192-core, 12-channel memory architecture with a 64KB page size kernel delivers compounding performance gains that are difficult to match. The processor's energy efficiency advantage — up to 35% better performance per watt — can help lower operating costs and cooling demands in the data center.
Whether you're running Hadoop batch jobs overnight, powering Spark-based analytics dashboards, or executing complex SQL decision-support queries, AmpereOne® M was purpose-built for exactly this kind of work. The benchmarks don't just show incremental progress — they show a platform designed from the ground up for the scale and memory intensity that modern data processing demands.
For complete details, visit the reference architecture documents directly:
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



