
How HPE and Ampere are Tripling Data Center Efficiency
How HPE and Ampere are Tripling Data Center Efficiency
How do you triple data center efficiency without sacrificing power? Sean Varley, VP Product Marketing, Ampere and Scott Shafer, VP, Server Advanced Development, HPE tackled the topic in our recent webinar, “How to Triple Efficiency, Double Performance, and Save in Your Data Center.” You can watch the webinar in its entirety here and read the recap and answers to audience questions below.
Key discussions points for increasing data center efficiency and performance include:
- Global data center electricity demands predicted to rise from 2% to up to 8% by 2030
- For a representative web service, Cloud Native Processors can deliver 3x data center efficiency, including:
- 2.5x greater performance per rack
- 2.8x lower power consumption
- Performance per rack is the new data center efficiency metric
- The HPE ProLiant RL300 Gen11 reduces friction for conversion to cloud native solutions
The state of data center power limits
We're currently utilizing about 2% of the global electricity demand and the projections from often cited research from Anders Andre from Huawei, is that it's going to go up from 2x to 4x by 2030. At the same time, we're seeing a lot of limits and moratoriums on data center expansion. In Ireland they've instituted moratoriums where they're having trouble supplying electricity to data centers. We're seeing the same things in Denmark, Amsterdam, and Singapore. West London put some moratoriums on data center build out, because they’re taking power away from residential neighborhoods. Even in the US, we've seen moratoriums in Virginia and Arizona. This is a trend, and it's something that we're going to talk a lot more about in terms of getting better efficiency out of your data center today.
Some of the calculations we’ve done show that if we continue to build out data centers the way that the industry has been built in the past—using legacy x86 processors—you will need about twice the power by 2025 and about 60% more datacenter space. However, if you build out with a cloud native approach, we change the entire trajectory of this trend to use 20% less power and 30% less data center space and still provide all the computing needs of the projected demand.
A use case for data center efficiency
Let's look at a use case involving a large software as a service or digital service provider with about 1.3 million users all hitting a web service at the same time. Some recent analysis we've conducted is based on a composite web service under service level constraints, and based on these very common web service components:
- NGINX: A popular front end reverse proxy and HTTP server that is highly utilized in the cloud today
- Redis: A key value store and common caching layer
- MemcacheD: An object caching layer for assets to make sure frequently accessed assets are quickly fetched.
- MySQL: A common relational database.
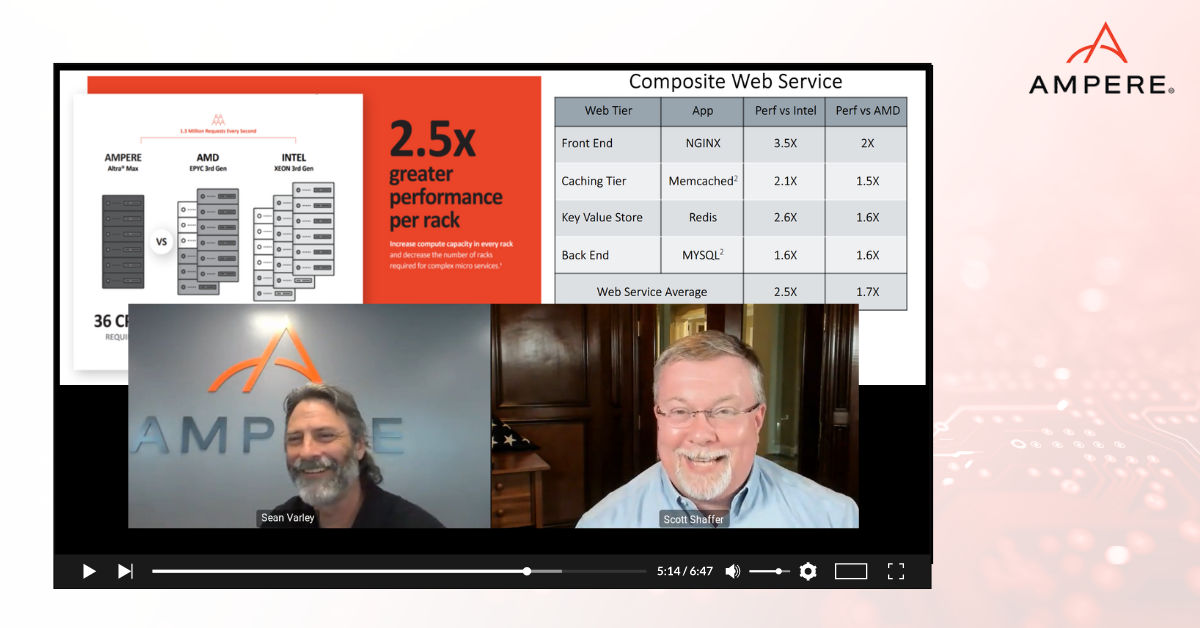
All four of these applications are highly utilized in many web services today. Comparing Ampere Altra Max to the Intel third generation Xeon line and the AMD third generation EPYC line we found we could get 478%, better in power efficiency with NGINX And 439%, better in Redis. So it goes on down the line. We've approximated a web service and came up with a composite of 2.5x better performance per rack than using Intel. The load is serviced with 36 Altra Max CPUs, A, AMD with 54, and Intel with 82 CPUs—so you can get a feel for the scalability of this platform.
If I can leave one thought in your mind, it’s that we're establishing a new metric with performance per rack. One of the reasons why we want to establish this performance per rack metric is because of the power. When you look at racks, this is a fundamental building block of every data center, every point of presence, you will find racks everywhere from hyperscale data centers to telco points of presence in central offices, to submarines.
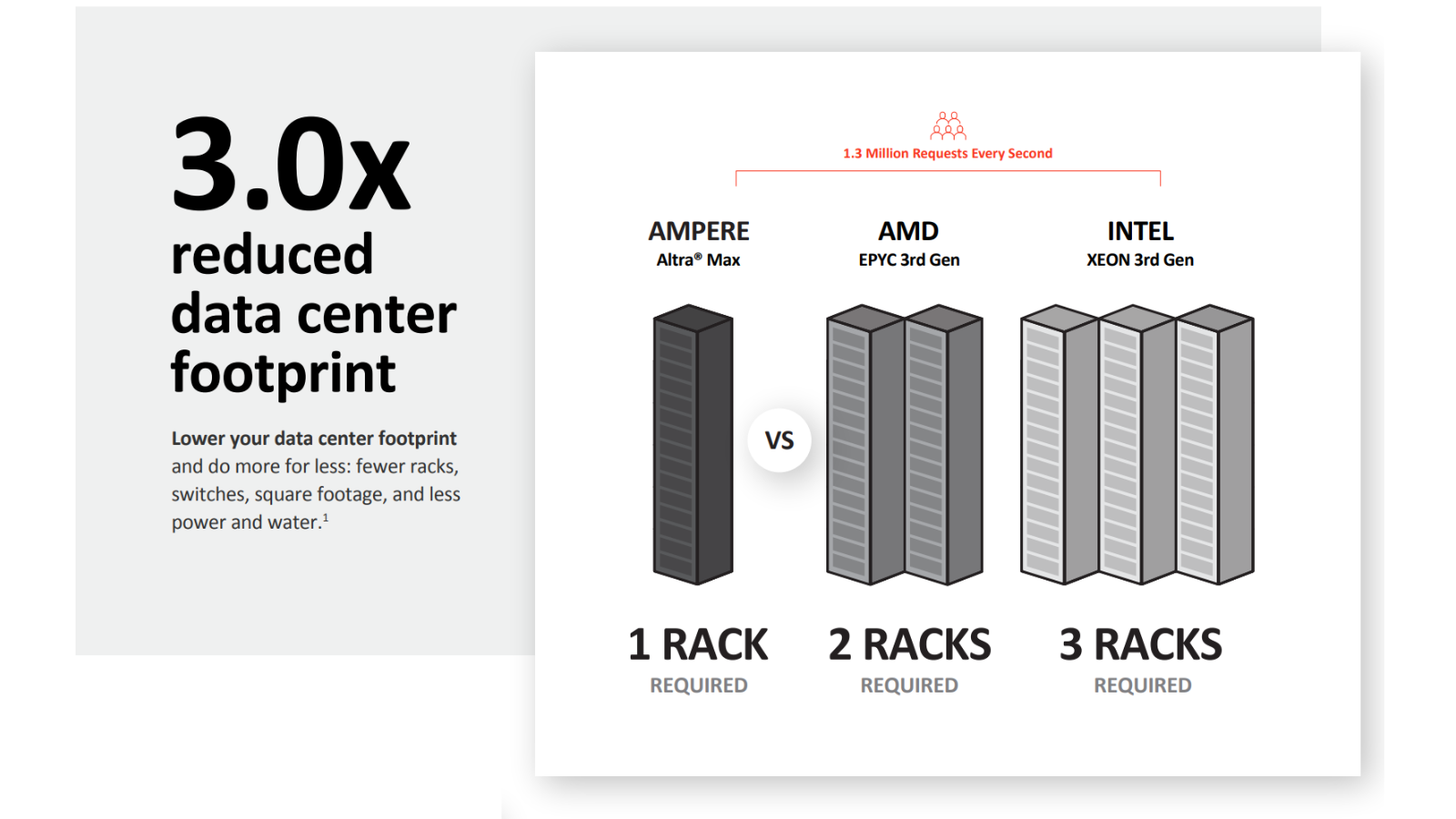
Anywhere you are racking a lot of servers, you'll find that humble rack, and the humble rack is always limited by a power budget. To serve 1.3 million requests, it takes 12.7 kilowatts with Ampere Altra Max. Contrast that with the legacy x86 ecosystem with almost 35 kilowatts for Intel.
At the rack level, you have that rack power budget. Once you blow through that power budget, you must go to the next rack. In this case, we've set at a point at 14 kilowatts, which is a reasonable point for many data centers in the world today while leaving some headroom for the equipment that goes at the top of the rack—like switches and power delivery and whatnot. This allows us to service 1.3 million requests in one rack.
 -Lower your data center footprint and do more for less: fewer racks, switches, square footage, and less power and water.
-Lower your data center footprint and do more for less: fewer racks, switches, square footage, and less power and water.
But if you look at the power consumption for the x86 ecosystem, it's going to take two racks, three racks for them to accomplish the same thing. So, you start to see these economies of scale, 1/3 of the rack space is required to service that load.
For the Ampere, Altra family, we have 4x the cores per rack. That's a lot of cores, we can pack them in there because they're so power efficient. This gives us 2.8x. lower power for the service delivered and 2.5x performance per rack. These are generational differences. Where do you deploy this? Like I mentioned earlier that that rack is kind of ubiquitous, it goes from the core data center all the way out to the edge, even into mobile environments, or containers, lots of different areas.
Performance and power efficiency are two things in combination needed to build much more sustainable data centers—from hyperscalers all the way out to the edge.
The HPE ProLiant RL300 Gen11 - Powered by Ampere Altra Max
"HPE has worked with Ampere to bring to market a 1Userver platform that delivers power and performance while ensuring that it fits within the traditional management ecosystem, regardless of what that is for our customers. It starts with the fact that you get a lot more cores at lower power and the ability to service your workload with less—I think that's significant. Not only does it use less power, which is very important to me, but you also do it with less servers and that means less money so everything is a win-win in these types of environments.
Outside of cloud native solutions, we're seeing customers forced to leave gaps in their data center because they're out of power, or they're out of their power budget, not because of their space budget. So, this really lets you optimize both. Performance per watt is key, but don't lose sight of the fact that there's just pure performance here.
There's strong delivery of performance in a host of applications and workloads. And this performance is incredibly consistent. Every single core—all 128 of them with an Altra Max installation—runs at the same clock rate. So, you don't have any core, any workloads sitting out on the last few cores that are being starved by the ones up front. That's not how this architecture works.
in their data center because they're out of power, or they're out of their power budget, not because of their space budget.”
From our standpoint, we think this is just great for those cloud native workloads, those applications that you're building, with these common building blocks, like Redis and MySQL—all those components.
Do more with less in your data center
Hard to believe that I'm about to say it, you can buy less, you don't have to buy so many servers, you can optimize for the workload, if your workload is servicing 1.3 million requests, then build it for that don't build it out for 10x. I'm super excited about this platform, because we're seeing the performance really deliver. The premise 10 years ago, was to take a phone processor and put it in a server to get really low power. What we got was really poor performance to go with it and a software ecosystem that wasn't ready. Now, all those things have come together.
We have a completely fleshed out software ecosystem, a whole bunch of choices operating systems, and a bunch of choices of applications, that are not just recompiled for ARM and the instruction set, but they're optimized for it. Therefore, you start to see these fantastic numbers. With this platform you get the optimal cost. And most importantly, you get optimal power usage.
Traditional ProLiant functionality with better performance
One of the big things we brought to this platform is our management solution, which we have provided for years for our enterprise offerings. This platform has the full suite of capabilities, including redundant power supplies, front mounted removable drives, and lights with all the info you need. But of course, our industry leading ILO platform, which gives you rich manageability, virtual media, a remote console, and all those things that you expect for Redfish compliance. You can control it remotely—all the things that a customer who's used ProLiant before would expect.
This platform and everything about it—the way memory works, the way storage works, the way I O works—is the same as a traditional ProLiant. In fact, it should fit right in alongside your traditional management solutions that know how to work with ILO. However, we've also recognized that our service provider customers are looking for something a little different, so the ProLiant, RL 300 Gen 11 allows service providers to deploy their own open BMC image.
Our goal is to make it frictionless. We want to enable you to get this platform deployed. If you're a service provider, deploy your open BMC image and then fit it right in alongside all your other platforms.
Audience questions and expert answers about data center efficiency
Following the webinar, Scott and Sean answered questions from the audience. Below is a summary of those discussions. If you have additional questions, please contact us and we’ll get answers to you right away.
Q: What are the requirements to be able to use OpenBMC with the RL300?
A: You must be capable of building your own OpenBMC from the source and digitally signing it with your internal PKI. Contact HPE at https://www.hpe.com/us/en/compute/openbmc-proliant-servers.html for more details and to sign up.
Q: Is this 2.5x performance with just migrating the apps to Ampere (Arm) right away or do we need some specialized tuning?
A: There is a growing library of tuning apps for individual applications. We have a number of open-source packages and tuning guides on the Ampere website. With all the support available, there is no need to recompile for the Arm environment. Most open-source components have already been optimized and are performing at high rates.
Q: How about disk access performance in Ampere compared against x86's
A: There are no differences in IO performance between the RL300 and x86 servers. The RL300 can support up to 10 NVMe Gen4 SSDs.
Q: How do I get a POC started for my current web services workload? Are there developer tools and guides?
A: Visit our website at: https://amperecomputing.com/where-to-buy and our developer center at: https://amperecomputing.com/developers
Q: Do you know how much power is consumed accessing by the tightly coupled memory (L1,2,3) vs the raw CPU consumption. Do you do any memory access optimization?
A. Ampere’s cache architecture is different. We’ve put an emphasis on L2 caches, and we inject data and instructions directly into those L2 caches. This is part of how we achieve power efficiency in our Cloud Native Processors.
Q: Any guidance on security objection handling and recent SPR accelerator performance?
A: The recently announced Sapphire Rapids has spurred a debate in the industry by integrating accelerators for networking, AI, memory transfer, and others Intel has chosen to focus on individual workloads. We’ve taken a different approach by creating general purpose CPUs with a lot of cores (up to 128) to service whatever workloads you need. The performance is going to be a product of the ability to accelerate any individual workload. When it becomes a small portion of the target space for applications, users pay the price -often in power- if that particular workload is not in use.
Built for sustainable cloud computing, Ampere’s first Cloud Native Processors deliver predictable high performance, platform scalability, and power efficiency unprecedented in the industry.
This blog is part of a series about data center efficiency.
- 5 Keys to Ultimate Data Center Efficiency and Performance
- 3 Reasons Expensive Power is the Biggest Data Center Challenge
- How to Shrink Your Data Center and Increase Capacity
- How Can Data Centers be More Sustainable?
Learn more about data center efficiency in our eBook
Triple Data Center Efficiency with Cloud Native Processors
Watch our webinar:
How to Triple Efficiency, Double Performance, and Save in Your Data Center
Ready to get started saving in your data center? Talk to our expert sales team about partnerships or get more information or trial access to Ampere Systems through our Developer Access Programs.
Footnote:
*The web services study here is based on performance and power data for many typical workloads using single node performance comparisons measured and published by Ampere Computing. Details and efficiency footnotes are available here.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



