
Power Your AI
Power Your AI
Power your applications and services with the best GPU-free alternative
Power your applications and services with the best GPU-free alternative

Ampere AI Solutions? > AI Solutions
Ampere AI Solutions? > AI Solutions
Ampere Optimized AI Frameworks
Ampere Optimized AI Frameworks
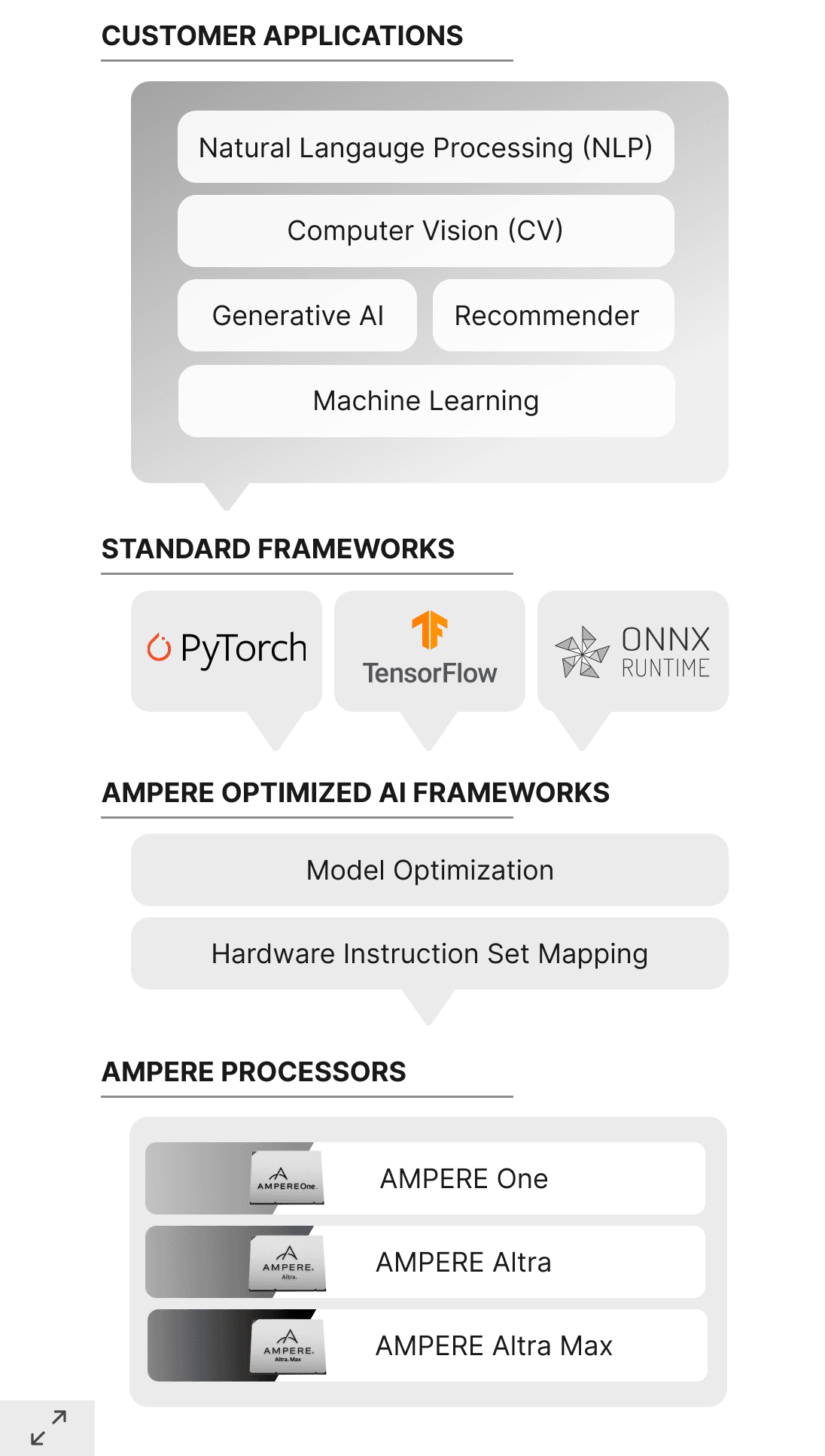
Ampere helps customers achieve superior performance for AI workloads by integrating optimized inference layers into common AI frameworks.
Main Components
-
Framework Integration Layer: Provides full compatibility with popular developer frameworks. Software works with the trained networks “as is”. No conversions or are required.
-
Model Optimization Layer: Implements techniques such as structural network enhancements, changes to the processing order for efficiency, and data flow optimizations, without accuracy degradation.
-
Hardware Acceleration Layer: Includes a “just-in-time”, optimization compiler that utilizes a small number of Microkernels optimized for Ampere processors. This approach allows the inference engine to deliver high-performance on all frameworks.

Ampere Model Library
AML is a collection of optimized AI models pretrained on standard datasets. The library contains scripts running the most common AI tasks. The models are available for Ampere customers to quickly and seamlessly build into their applications.
AML Benefits Include:
-
Benchmarking AI architecture with different frameworks
-
Accuracy testing of AI models on application-specific data
-
Comparison of AI architectures
-
Conducting tests on AI architectures
Downloads
Downloads

Ampere Optimized PyTorch
Ampere Optimized PyTorch
Ampere's inference acceleration engine is fully integrated with Pytorch framework. Pytorch models and software written with Pytorch API can run as-is, without any modifications.

Ampere Optimized TensorFlow
Ampere Optimized TensorFlow
Ampere's inference acceleration engine is fully integrated with Tensorflow framework. Tensorflow models and software written with Tensorflow API can run as-is, without any modifications.
Ampere Optimized ONNX Runtime
Ampere Optimized ONNX Runtime
Ampere's inference acceleration engine is fully integrated with ONNX Runtime framework. ONNX models and software written with ONNX Runtime API can run as-is, without any modifications.

Ampere Model Library (AML)
Ampere Model Library (AML)
Ampere Model Library (AML) is a collection of AI model architectures that handle the industry's most demanding workloads. Access the AML open GitHub repository to validate the excellent performance of the Ampere Optimized AI Frameworks on our Ampere Altra family of cloud-native processors.
Documentation
Documentation
Benefits & Features
-
Up to 5x performance acceleration
-
Seamless “out-of-the-box” deployment
- No additional coding required
- No API changes
- Instantaneous integration
-
All model types are supported
-
Native support of FP16 data format
- Double performance over FP32 data format
- No loss in accuracy
- Supports models trained in FP16, FP32, and mixed data formats
- Seamless conversion from the FP32 data format
-
Easily accessible publicly hosted Docker images allowing for instantaneous deployment
-
Free of charge
Native FP16 Support
Ampere hardware uniquely offers native support of the FP16 data format providing nearly 2X speedup over FP32 with almost no accuracy loss for most AI models.
FP16, or "half-precision floating point," represents numbers using 16 bits, making computations faster and requiring less memory compared to the FP32 (single precision) data format. The FP16 data format is widely adopted in AI applications, specifically for AI inference workloads. It offers distinct advantages, especially in tasks like neural network inference, which require intensive computations and real-time responsiveness. Utilizing FP16 enables accelerated processing of AI models, resulting in enhanced performance, optimized memory usage, and improved energy efficiency without compromising on accuracy.
> Learn more about the difference between FP16 and FP32 data formats
> Benefits of FP16 for Computer Vision
> Benefits of FP16 for Natural Language Processing
> Benefits of FP16 for Recommender Engines
FAQs
FAQs
Resources
Resources
Briefs
Brief
Wallaroo and Ampere Accelerate AI Inference by 7X
Ampere
Brief
AI Inference on Ampere Altra Max
Ampere
Brief
AI- Ampere Vs. Graviton
Ampere
Brief
AI Inference on Azure
Ampere
Brief
Ampere AI Efficiency: Computer Vision
Ampere
Brief
Ampere AI Efficiency: Natural Language Processing
Ampere
Brief
Ampere AI Efficiency: Recommender Engine
Ampere
Tutorials
Publications
Podcasts
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



