


AI Efficiency
Reduce power consumption without sacrificing performance and build a sustainable future.
Right-Sizing AI Compute
Get the best price/performance benefits in the cloud and better value for AI inferencing compute
FP16 vs FP32
FP16 data format boosts AI inference performance in the cloud
Customer Testimonials
Customer Testimonials
![]()
"Using Ampere A1 instances on OCI with integrated Ampere Optimized AI library, we managed to right-size compute providing price-performance advantage on deep learning inferencing relative to GPUs and to other CPUs. We found an order of magnitude or more reduction in cloud resource costs, measured at 4 operating points for 2 cloud vendors, while avoiding operational complexity for changes in model serving resource needs and cloud offerings."
-Madhuri Yechuri, CEO, Elotl
![]()
"Switching to Ampere-optimized Tensorflow running on OCI A1 instances has enabled us to achieve a 75 percent cost saving for the training of the algorithms for our plastics and fabrics identification machines, while lowering our CO2 emissions - thanks to Ampere Altra’s high energy efficiency."
-Martin Holicky, CEO, Matoha

“This breakthrough Wallaroo/Ampere solution allows enterprises to improve inference performance, increase energy efficiency, and balance their ML workloads across available compute resources much more effectively, all of which is critical to meeting the huge demand for AI computing resources today also while addressing the sustainability impact of the explosion in AI.“
-Vid Jain, chief executive officer of Wallaroo.AI

AI Benchmarking
AI Benchmarking
Ampere Optimized AI Frameworks deliver a significant inference performance improvement to applications developed on all major AI frameworks. Ampere AI currently supports the following frameworks:
- PyTorch
- TensorFlow
- ONNX
All Docker images can be conveniently downloaded from the Ampere Computing AI Docker Hub. The software is free and runs seamlessly on all Ampere products.
Ampere AI optimized frameworks + Ampere processors deliver disruptive value for AI inference:
-
High Performance: Up to 4X performance advantage compared to CPUs built on x86 architecture
-
Energy Efficiency: 2.8x less power use than x86 processors and 3x smaller footprint. Learn More
-
Scalability: Optimized architecture, core counts surpassing x86 processors of AMD and Intel, and improved memory bandwidth accelerated by Ampere Optimized AI Frameworks.
-
Compatibility: Robust ecosystem offering extensive support from leading AI frameworks, libraries, and software tools, facilitating effortless integration.
System configurations, components, software versions, and testing environments that differ from those used in Ampere’s tests may result in different measurements than those obtained by Ampere. The system configurations and components used in our testing are detailed here
Ampere Optimized AI
Ampere Optimized AI
Ampere Altra and Ampere Altra Max, with high performance Ampere optimized frameworks, offers the best-in-class Artificial Intelligence inference performance for all AI applications developed in the most popular frameworks including PyTorch, Tensorflow, and ONNXRuntime. Ampere Model Library (AML) offers pretrained models to help accelerate AI development.
Ampere helps customers achieve superior performance for AI workloads by integrating optimized inference layers into common AI frameworks.
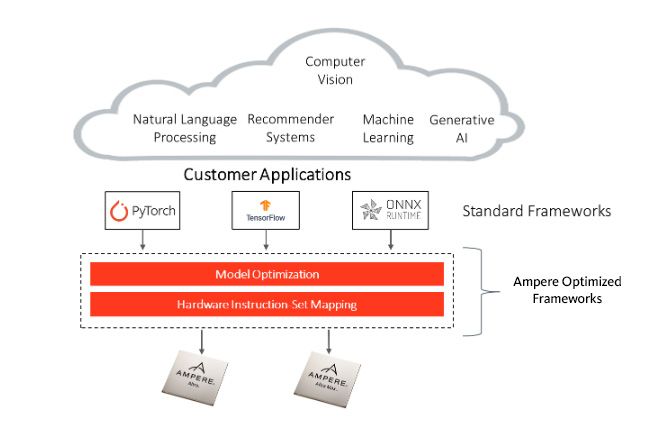
Main Components
-
Framework Integration Layer: Provides full compatibility with popular developer frameworks. Software works with the trained networks “as is”. No conversions or are required.
-
Model Optimization Layer: Implements techniques such as structural network enhancements, changes to the processing order for efficiency, and data flow optimizations, without accuracy degradation.
-
Hardware Acceleration Layer: Includes a “just-in-time”, optimization compiler that utilizes a small number of Microkernels optimized for Ampere processors. This approach allows the inference engine to deliver high-performance on all frameworks.
-
Up to 5x performance acceleration
-
Seamless “out-of-the-box” deployment
- No additional coding required
- No API changes
- Instantaneous integration
-
All model types are supported
-
Native support of FP16 data format
- Double performance over FP32 data format
- No loss in accuracy
- Supports models trained in FP16, FP32, and mixed data formats
- Seamless conversion from the FP32 data format
-
Easily accessible publicly hosted Docker images allowing for instantaneous deployment
-
Free of charge
AML is a collection of optimized AI models pretrained on standard datasets. The library contains scripts running the most common AI tasks. The models are available for Ampere customers to quickly and seamlessly build into their applications.
AML Benefits Include:
-
Benchmarking AI architecture with different frameworks
-
Accuracy testing of AI models on application-specific data
-
Comparison of AI architectures
-
Conducting tests on AI architectures
Native FP16 Support
Ampere hardware uniquely offers native support of the FP16 data format providing nearly 2X speedup over FP32 with almost no accuracy loss for most AI models.
FP16, or "half-precision floating point," represents numbers using 16 bits, making computations faster and requiring less memory compared to the FP32 (single precision) data format. The FP16 data format is widely adopted in AI applications, specifically for AI inference workloads. It offers distinct advantages, especially in tasks like neural network inference, which require intensive computations and real-time responsiveness. Utilizing FP16 enables accelerated processing of AI models, resulting in enhanced performance, optimized memory usage, and improved energy efficiency without compromising on accuracy.
Learn more about the difference between FP16 and FP32 data formats
Benefits of FP16 for Computer Vision
Applications
Applications
Downloads: Ampere Optimized AI Software


Ampere Optimized PyTorch
Ampere Optimized PyTorch
Ampere's inference acceleration engine is fully integrated with Pytorch framework. Pytorch models and software written with Pytorch API can run as-is, without any modifications.

Ampere Optimized TensorFlow
Ampere Optimized TensorFlow
Ampere's inference acceleration engine is fully integrated with Tensorflow framework. Tensorflow models and software written with Tensorflow API can run as-is, without any modifications.
Ampere Optimized ONNX Runtime
Ampere Optimized ONNX Runtime
Ampere's inference acceleration engine is fully integrated with ONNX Runtime framework. ONNX models and software written with ONNX Runtime API can run as-is, without any modifications.

Ampere Model Library (AML)
Ampere Model Library (AML)
Ampere Model Library (AML) is a collection of AI model architectures that handle the industry's most demanding workloads. Access the AML open GitHub repository to validate the excellent performance of the Ampere AI with optimized frameworks on our Ampere Altra family of cloud-native processors.
FAQs
FAQs
Resources
Resources
Briefs
Tutorials
Documentation
Publications
Podcast

Ampere Computing
4655 Great America Parkway
Suite 601 Santa Clara, CA 95054

